This article walks through four ways to implement a TCP echo server on Linux: single-process single-threaded, multi-process, multi-threaded, and thread pool-based. The core challenge is understanding the TCP connection model, concurrency strategies, and resource cleanup mechanisms. Keywords: TCP echo server, socket programming, thread pool.
The technical specifications are easy to scan
| Parameter | Details |
|---|---|
| Language | C++ |
| Protocol | TCP / IPv4 |
| Runtime Environment | Linux |
| Core APIs | socket, bind, listen, accept, connect, read, write |
| Concurrency Models | Single-threaded, Multi-process, Multi-threaded, Thread pool |
| Core Dependencies | pthread, sys/socket.h, arpa/inet.h, netinet/in.h |
| Testing Tools | telnet, netstat |
| Original Article Popularity | 658 views, 25 likes |
TCP programming starts with connection semantics
UDP works well for fast data delivery, but it does not guarantee reliability and does not maintain connection state. TCP is fundamentally different. It requires a connection to be established first, and only then supports ordered, reliable data transmission.
On the server side, socket only creates the socket; bind attaches it to a port; listen switches the socket into listening mode; and accept removes a connection from the kernel’s completed handshake queue and returns a new communication file descriptor.
The engineering differences between TCP and UDP are clear
TCP is a byte-stream protocol. It does not provide natural message boundaries, so developers must handle packet sticking and packet splitting themselves. Although an echo server is simple, it is still enough to demonstrate the TCP connection lifecycle and concurrency model.
int listensockfd = socket(AF_INET, SOCK_STREAM, 0); // Create a TCP listening socket
bind(listensockfd, (struct sockaddr*)&local, sizeof(local)); // Bind the local port
listen(listensockfd, 16); // Start listening and wait for client connections
int sockfd = accept(listensockfd, (struct sockaddr*)&client, &len); // Obtain a communication socketThis code shows the most important startup path of a TCP server.
The single-threaded version is best for learning the basic TCP flow
The value of the single-process single-threaded version is not concurrency. Its value lies in making the call sequence completely clear. The server blocks on accept, enters a read/write loop after it gets a connection, and returns to accept only after the client disconnects.
The advantages of this model are straightforward: the structure is minimal, the logs are easy to read, and troubleshooting is simple. The drawback is equally direct: it can serve only one client at a time, and later connections must wait in line.
serviceIO is the core location of the echo logic
The server reads data from sockfd and writes back a string with a prefix. A return value of from read means the peer closed the connection normally, while a negative value indicates an error.
ssize_t n = read(sockfd, inbuffer, sizeof(inbuffer) - 1); // Read data from the client
if (n > 0) {
inbuffer[n] = 0; // Manually append the string terminator
std::string echo = "server echo# ";
echo += inbuffer; // Append the echoed content
write(sockfd, echo.c_str(), echo.size()); // Write the response back to the client
}This code implements the smallest runnable TCP echo service.
The multi-process version gains concurrency through fork
In the multi-process model, the parent process handles only accept. Whenever a client connects, the server calls fork to create a child process for communication. That allows the parent process to return to the listening loop immediately and serve multiple clients concurrently.
However, the multi-process model introduces a classic problem: if exited child processes are not reclaimed, they become zombie processes. You must design a cleanup mechanism, or system resources will gradually be exhausted and concurrency will collapse.
Zombie process handling usually follows two mainstream approaches
The first approach uses a double fork. The grandchild process handles the workload, the child exits quickly, and the parent reaps it with waitpid. The second approach is simpler: ignore SIGCHLD and let the kernel clean up exited child processes automatically.
signal(SIGCHLD, SIG_IGN); // Ignore child-exit signals to avoid zombie processes
pid_t id = fork(); // Create a child process for the current client
if (id == 0) {
close(_listensockfd); // The child no longer listens; it only handles communication
serviceIO(sockfd, clientaddr); // Process IO for the current client
close(sockfd); // Close the connection after communication ends
exit(0);
}
close(sockfd); // The parent closes the unused communication fdThis code reflects responsibility separation and file descriptor lifecycle management in the multi-process model.
The multi-threaded version reduces the system overhead of the process model
The multi-threaded version keeps the same structure: the main thread runs accept, and a worker unit handles each connection. The difference is that it replaces fork with pthread_create. Compared with processes, threads are lighter to create and cheaper to context-switch.
The key detail is that the thread entry function must match the signature required by pthread_create. A normal member function implicitly carries a this pointer, so it cannot be used directly as the entry point. In practice, developers usually solve this with a static function plus a parameter wrapper object.
ThreadData makes thread argument passing cleaner
The thread function must receive sockfd, the client address, and a way to call the class member serviceIO, so a struct is used to package these values together.
class ThreadData {
public:
ThreadData(TcpServer* ts, int fd, const InetAddr& addr)
: _this(ts), _sockfd(fd), _addr(addr) {}
~ThreadData() { close(_sockfd); } // Automatically close the fd when the thread exits
TcpServer* _this;
int _sockfd;
InetAddr _addr;
};This structure gives the thread all connection-handling context in one step and simplifies resource cleanup.
The thread pool version is the closest to a production-ready model
Creating one thread per connection works at low concurrency, but it causes two problems under high load: thread creation and destruction are expensive, and the number of threads can grow without control. A thread pool exists to solve both issues.
A thread pool creates a fixed number of worker threads in advance. The main thread handles only accept, packages client-processing logic as tasks, and submits those tasks to a queue. Worker threads pull tasks from the queue and execute them repeatedly.
Lambda tasks make thread pool integration natural
Here, the task type can be defined as std::function<void()>. As long as this, sockfd, and clientaddress are captured in the lambda capture list, the task can execute serviceIO completely.
using task_t = std::function<void()>;
ThreadPool
<task_t>::Instance()->Enqueue([this, sockfd, clientaddress]() {
this->serviceIO(sockfd, clientaddress); // Process the client request in a thread pool worker
close(sockfd); // Close the communication fd after the task finishes
});This code converts each client connection into a schedulable task and enables thread reuse and concurrency limit control.
telnet and netstat are extremely cost-effective debugging tools
telnet can connect directly to a target IP and port, which makes it a fast way to verify whether the server is listening and whether it can send and receive plaintext data. For an echo server, this is much more efficient than writing a client from scratch every time.
netstat -natp helps you inspect connection states, listening ports, and the processes associated with them. If the client and server run on the same machine, you can usually see a pair of ESTABLISHED entries representing both ends of the connection.
Long-lived and short-lived connections affect thread pool behavior
The current echo server uses a long-lived connection model. A worker thread keeps serving the same client until the peer disconnects. This works well for chat systems, games, and other scenarios with frequent interaction.
If you switch to a short-lived connection model, serviceIO closes the connection after one read/write cycle. The thread returns to the pool more quickly, which is a better fit for request-response patterns such as HTTP.
These four versions are really a step-by-step evolution of the same TCP model
The single-threaded version answers, “Can I write it at all?” The multi-process version answers, “Can it handle concurrency?” The multi-threaded version asks, “Can concurrency cost less?” The thread pool version answers, “Can concurrency stay controlled and stable?”
From a teaching perspective, these four stages connect the most important concepts in Linux TCP server development: connection establishment, blocking I/O, file descriptor management, process and thread switching, and task scheduling.
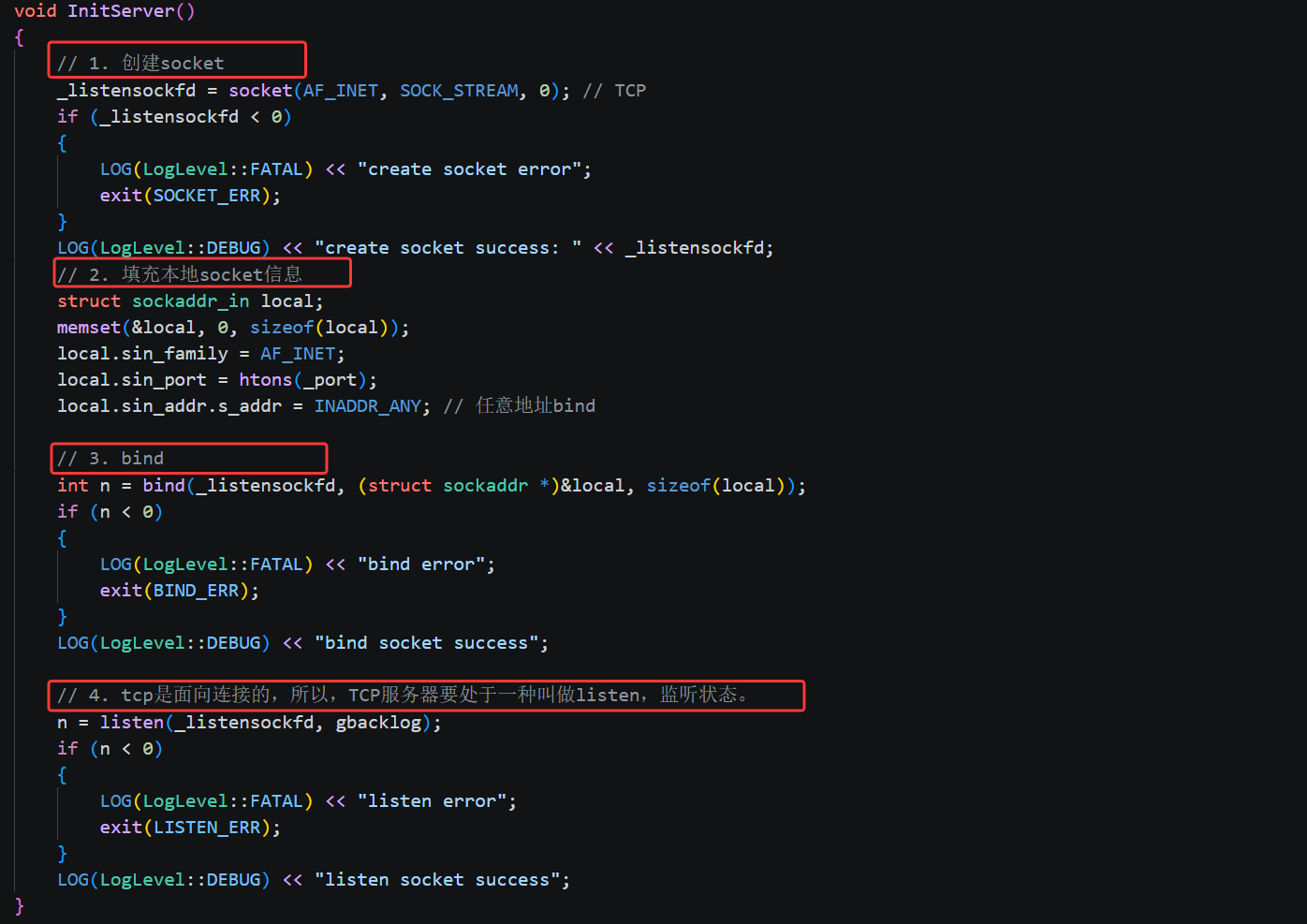 AI Visual Insight: This diagram shows the full TCP server initialization sequence: first create an
AI Visual Insight: This diagram shows the full TCP server initialization sequence: first create an AF_INET + SOCK_STREAM socket, then fill in sockaddr_in, call bind to attach the port and INADDR_ANY, and finally call listen to create the kernel listening queue. It highlights the separation between the listening socket and the communication sockets later returned by accept.
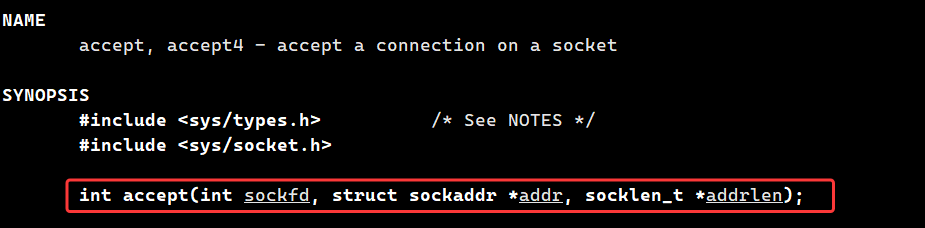 AI Visual Insight: This diagram focuses on the meaning of the three
AI Visual Insight: This diagram focuses on the meaning of the three accept parameters: the first is the listening file descriptor, and the latter two are output address parameters. It shows that accept removes a request from the queue of fully established TCP handshakes and generates a dedicated communication file descriptor for each client. That behavior is fundamental to TCP’s connection-oriented model.
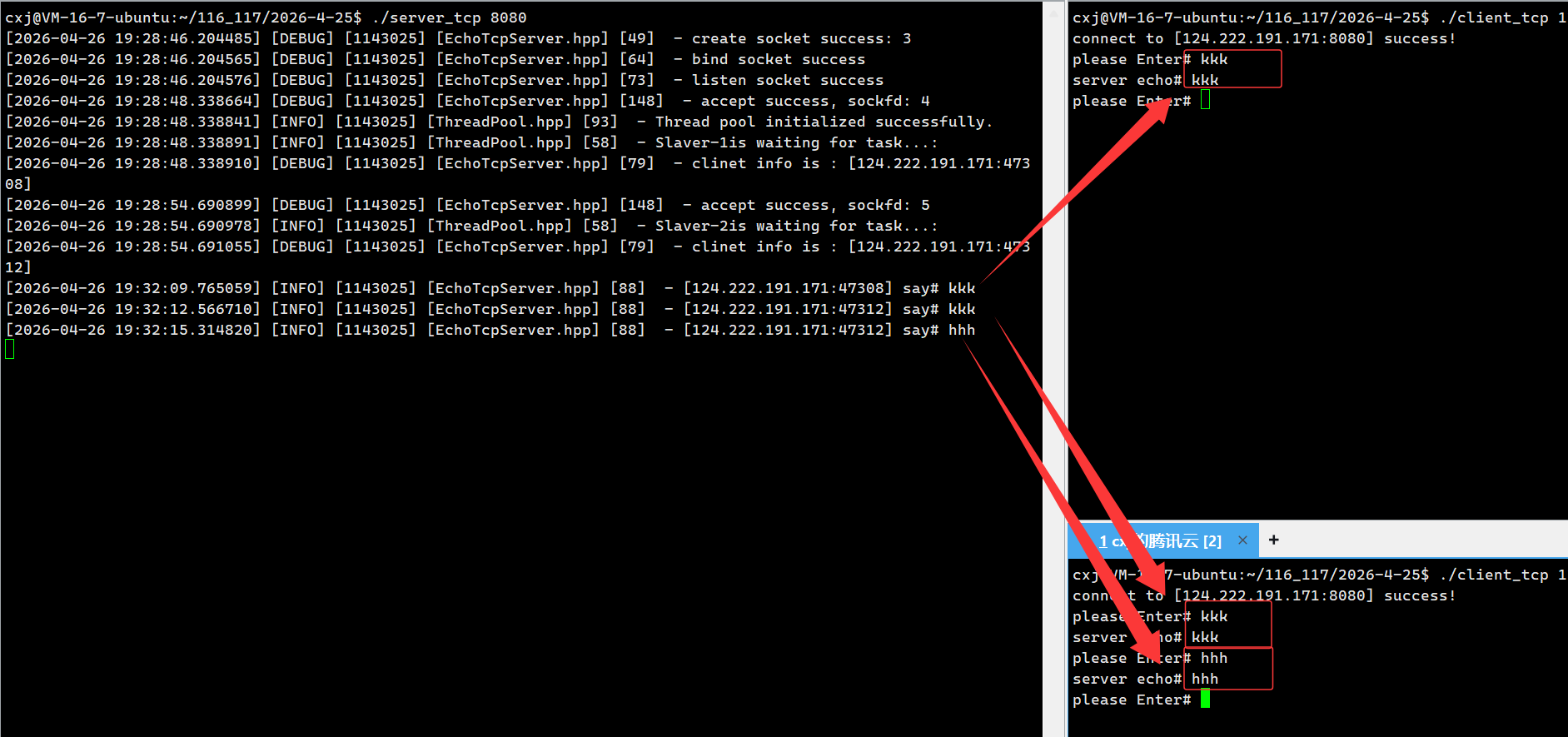 AI Visual Insight: The image shows multiple client messages being processed and echoed successfully by worker threads in the thread pool. This demonstrates that the main thread is responsible only for accepting connections, while business I/O has been dispatched to background threads. The result directly proves that the thread reuse model improves concurrency control while preserving functional correctness.
AI Visual Insight: The image shows multiple client messages being processed and echoed successfully by worker threads in the thread pool. This demonstrates that the main thread is responsible only for accepting connections, while business I/O has been dispatched to background threads. The result directly proves that the thread reuse model improves concurrency control while preserving functional correctness.
The FAQ section answers the most common questions
Why does a TCP server need two sockets?
The listening socket handles only bind, listen, and accept; it does not participate in actual reads or writes. The communication socket returned by accept serves one specific client. This separation allows the kernel to manage multiple connections at the same time.
For TCP concurrency, should you choose multi-process or multi-threading first?
For learning, it is worth implementing both. In engineering practice, multi-threading or a thread pool is usually the first choice because process switching and memory copying are more expensive. However, multi-process designs provide stronger isolation and fit scenarios with stricter fault containment requirements.
Why is the thread pool version more suitable for production?
Because it keeps the number of threads fixed, avoids unlimited thread creation as the number of connections grows, and reuses existing worker threads to reduce the overhead of frequent creation and destruction. The overall result is a more stable and predictable system.
Core Summary: This article systematically reconstructs the implementation path of a Linux TCP echo server, covering the transition from UDP-style thinking to TCP, the socket/bind/listen/accept/connect call chain, and the design differences, resource management, and testing methods behind four concurrency models: single-threaded, multi-process, multi-threaded, and thread pool.