This article breaks down three core Redis cache failure patterns in high-concurrency shop query systems: cache penetration, cache breakdown, and cache avalanche. It also provides practical Java code examples and architectural trade-offs. The main challenges include sudden traffic spikes overwhelming the database, hot key expiration, and batch expiration jitter. Keywords: Redis, cache breakdown, Bloom filter.
| Technical Specification | Details |
|---|---|
| Language | Java |
| Framework | Spring Boot, MyBatis Plus |
| Cache Protocols | Redis String, RedisBloom, distributed locks |
| Core Dependencies | StringRedisTemplate, Redisson, Guava, Caffeine, Sentinel |
| GitHub Stars | Not provided in the source material |
Shop query caching must handle cache hits, null values, and database fallback together.
Shop detail queries are a classic read-heavy, write-light workload. The most basic pattern is: query the cache first, fall back to the database on a miss, and then write the result back to the cache. For updates, use the pattern “update the database first, then delete the cache” to reduce the stale-data window.
The value of a transaction is not in Redis itself, but in guaranteeing atomic updates across multiple database tables. Only after the database transaction commits successfully should you delete the cache. Otherwise, you can end up in an invalid state where the cache is deleted but the database update fails.
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if (id == null) {
return Result.fail("Shop ID must not be null"); // Validate input parameters
}
updateById(shop); // Update the database first
stringRedisTemplate.delete("cache:shop:" + id); // Then delete the cache
return Result.ok();
}This code implements the baseline write path for cache consistency.
Cache penetration happens when requests keep querying data that does not exist.
When cache penetration occurs, the cache does not contain the data and the database does not contain it either, so every request falls through to the database. If an attacker continuously generates requests for nonexistent IDs, the database connection pool can be exhausted quickly, while SQL logs and slow query logs also grow sharply.
The most common solution is to cache a null object or empty string with a short TTL. The key is not just to “write a null value,” but to “return immediately when the null marker is hit.” Otherwise, the application will still query the database repeatedly.
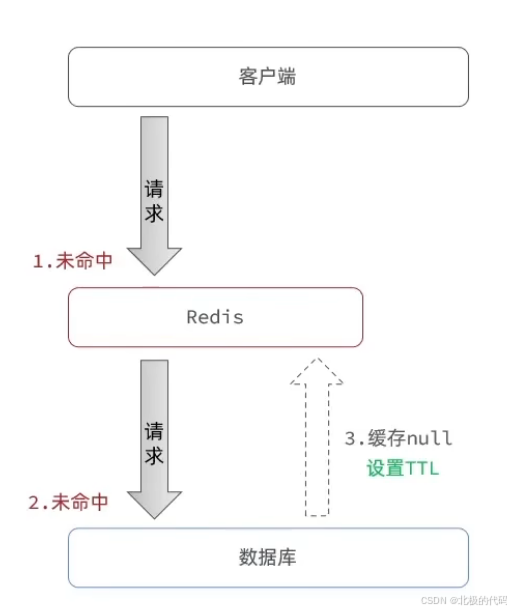 AI Visual Insight: This diagram shows the interception flow for cache penetration. The request first checks Redis. If the database confirms that the target does not exist, the system writes a null marker back into the cache layer with a short TTL to limit memory usage, preventing repeated invalid requests from continuing to penetrate the database.
AI Visual Insight: This diagram shows the interception flow for cache penetration. The request first checks Redis. If the database confirms that the target does not exist, the system writes a null marker back into the cache layer with a short TTL to limit memory usage, preventing repeated invalid requests from continuing to penetrate the database.
public Shop queryById(Long id) {
String key = "cache:shop:" + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class); // Hit valid cached data
}
if (shopJson != null) {
return null; // Hit cached empty string and block immediately
}
Shop shop = getById(id); // Fall back to the database
if (shop == null) {
stringRedisTemplate.opsForValue().set(key, "", 2, TimeUnit.MINUTES); // Cache null value to prevent penetration
return null;
}
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), 30, TimeUnit.MINUTES); // Write normal data back to cache
return shop;
}This code distinguishes among three states at the same time: valid cache hit, null-value hit, and complete cache miss.
Bloom filters are well suited for fast existence checks before requests enter the cache path.
When the ID space is large and malicious probing is frequent, a Bloom filter is more front-loaded than null-value caching. It can determine that “an ID definitely does not exist” before the request even reaches Redis or the database. The trade-off is a very low false-positive rate, plus the need for rebuilds and incremental maintenance.
In a multi-instance Redis deployment, prefer RedisBloom over an in-JVM Guava BloomFilter. RedisBloom is naturally shared and better suited for distributed systems, while Guava is more appropriate for monolithic services or demo environments.
@PostConstruct
public void initBloomFilter() {
List
<Long> allIds = shopMapper.selectAllIds();
for (Long id : allIds) {
bloomFilter.put(id); // Load existing IDs during startup
}
}
public Shop getShopById(Long id) {
if (!bloomFilter.mightContain(id)) {
return null; // Definitely does not exist, return immediately
}
return queryById(id); // Then enter the cache query path
}This code moves penetration protection forward to the Bloom filter layer.
Cache avalanche is not about one key failing, but many keys expiring at the same time.
A cache avalanche is usually triggered by uniform TTL settings, a Redis outage, or network failures. Unlike cache breakdown, an avalanche affects a batch of keys, so the database suffers a broad impact instead of a single-key hotspot.
The first-priority solution is to add random offsets to TTL values so expiration times are spread out. For hot business paths, combine this with cache prewarming, multi-level caching, and rate limiting with graceful degradation to avoid another traffic surge during recovery.
public void saveShopToCache(Shop shop) {
long baseTtl = 3600;
long randomOffset = ThreadLocalRandom.current().nextInt(300);
long ttl = baseTtl + randomOffset; // Add random offset to avoid simultaneous expiration
stringRedisTemplate.opsForValue().set(
"shop:" + shop.getId(),
JSONUtil.toJsonStr(shop),
ttl,
TimeUnit.SECONDS
);
}This code spreads out cache expiration times to reduce the probability of a cache avalanche.
Multi-level caching and prewarming improve system resilience during a cache avalanche.
A local Caffeine cache can serve as a fallback when Redis is briefly unavailable, which makes it a strong fit for hot-read scenarios. The downside is that data is not fully consistent across multiple application instances, so it is better used as a performance layer rather than a strong-consistency layer.
Cache prewarming is useful during startup or before promotional events. You can preload the top-N best-selling shops into the cache so the first wave of traffic does not go straight to the database.
private final Cache<Long, Shop> localCache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();This configuration creates a local hot-data cache and improves system tolerance when Redis is under stress or temporarily unavailable.
Cache breakdown occurs when a hot key expires and a large number of concurrent requests hit the database at once.
Typical breakdown targets include viral products, popular shops, and homepage configuration data with high QPS. After the cache expires, if 5,000 requests query the database at the same time, the database can be overwhelmed by concurrent access to the same key.
The most common solution is a mutex lock. The principle is to allow only one thread to rebuild the cache, while the others wait or retry briefly. To avoid duplicate database queries after the lock is released, you must implement Double Check.
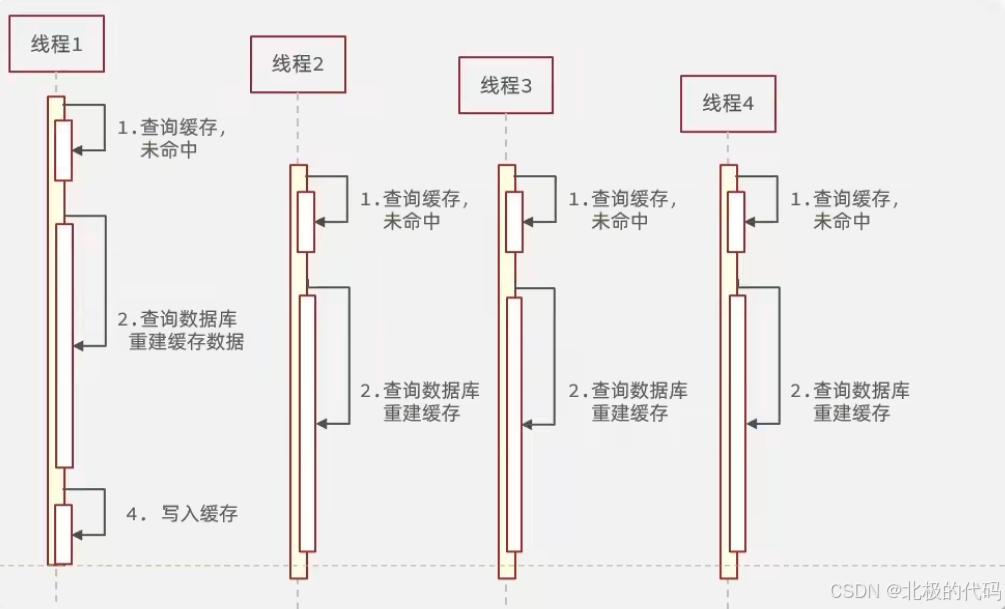 AI Visual Insight: This diagram shows the concurrency amplification effect when a hot key expires. Multiple requests detect a cache miss at the same moment and then converge on the database, exhausting the connection pool and causing CPU spikes. This is the standard timing pattern of cache breakdown.
AI Visual Insight: This diagram shows the concurrency amplification effect when a hot key expires. Multiple requests detect a cache miss at the same moment and then converge on the database, exhausting the connection pool and causing CPU spikes. This is the standard timing pattern of cache breakdown.
public Shop queryWithMutexCache(Long id) {
String key = "cache:shop:" + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class); // Hit cached data
}
if (shopJson != null) {
return null; // Hit cached null value
}
String lockKey = "lock:shop:" + id;
try {
boolean isLock = tryLock(lockKey); // Try to acquire the mutex lock
if (!isLock) {
Thread.sleep(50); // If lock acquisition fails, sleep briefly and retry
return queryWithMutexCache(id);
}
String again = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(again)) {
return JSONUtil.toBean(again, Shop.class); // Double Check to avoid duplicate DB queries
}
if (again != null) {
return null; // Double Check hit cached null value
}
Shop shop = getById(id); // Actual database fallback
if (shop == null) {
stringRedisTemplate.opsForValue().set(key, "", 2, TimeUnit.MINUTES); // Prevent penetration
return null;
}
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), 30, TimeUnit.MINUTES); // Write back to cache
return shop;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
} finally {
unlock(lockKey); // Release the lock
}
}This code implements a combined defense of “mutex lock + Double Check + null-value caching.”
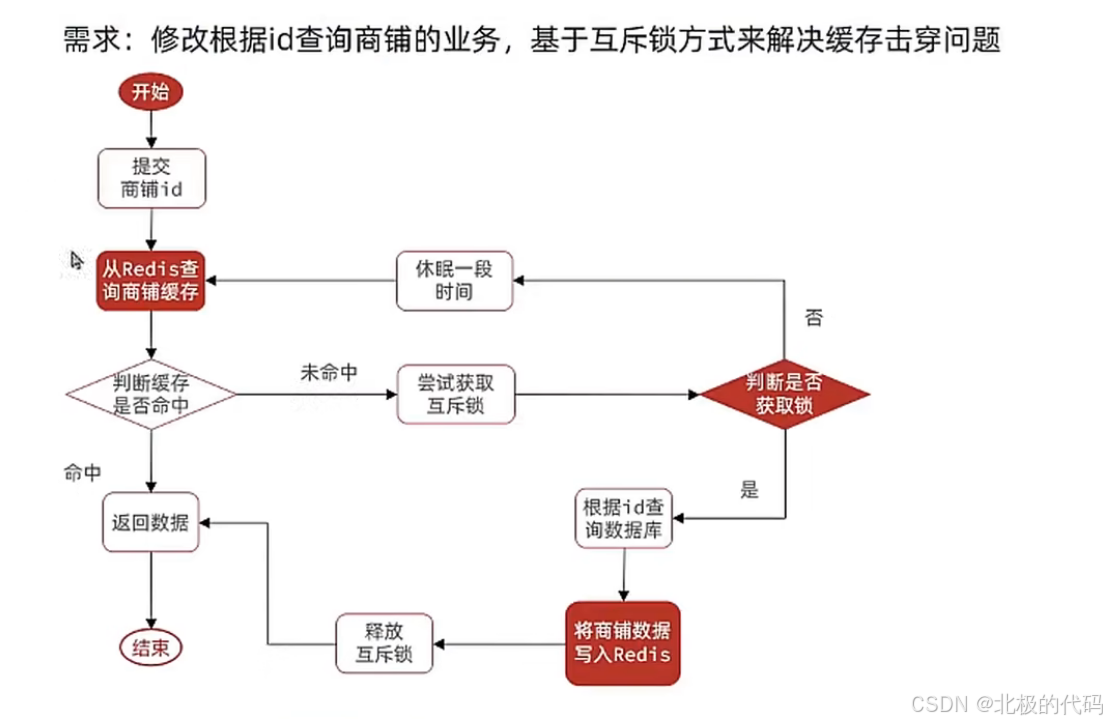 AI Visual Insight: This diagram presents the full workflow for resolving cache breakdown in shop queries with a mutex lock. It clearly marks six key stages: cache lookup, lock contention, secondary validation, database fallback, cache write-back, and lock release. It maps directly to a service-layer implementation.
AI Visual Insight: This diagram presents the full workflow for resolving cache breakdown in shop queries with a mutex lock. It clearly marks six key stages: cache lookup, lock contention, secondary validation, database fallback, cache write-back, and lock release. It maps directly to a service-layer implementation.
Logically expired data is a good fit for latency-sensitive scenarios.
Logical expiration does not let the cache entry physically expire. Instead, it stores an expiration timestamp inside the cached value. Even if a request reads logically expired data, the application returns the stale value first and triggers an asynchronous refresh in the background. This design sacrifices short-term consistency in exchange for low latency and high throughput.
Production-ready cache protection should use layered defenses instead of isolated fixes.
A practical shop query solution usually looks like this: parameter validation blocks invalid requests, a Bloom filter blocks nonexistent IDs, Redis null-value caching blocks penetration, hot keys use mutex locks or logical expiration to prevent breakdown, randomized TTL and prewarming reduce avalanche risk, Sentinel provides rate limiting and graceful degradation, and Redis Cluster ensures high availability.
If the business requires strong consistency, prefer “mutex lock + cache deletion.” If the priority is low latency, prefer “logical expiration + asynchronous refresh.” If you are preparing for a major traffic surge, you must also add “local cache + rate limiting + prewarming.”
FAQ
Q1: What is the core difference among cache penetration, cache breakdown, and cache avalanche?
A: Cache penetration means querying data that does not exist. Cache breakdown means a single hot key expires. Cache avalanche means a large number of keys fail or expire at the same time. Penetration affects request validity, breakdown affects hot-key concurrency, and avalanche affects overall system stability.
Q2: Why is Double Check mandatory in the mutex-lock approach?
A: When a thread acquires the lock, a previous thread may already have rebuilt the cache and written the data back. Without checking the cache again, later threads still query the database redundantly. In that case, the lock only serializes the cost instead of actually reducing database fallbacks.
Q3: In practice, should you prioritize null-value caching, Bloom filters, or logical expiration?
A: Null-value caching fits most scenarios and has the lowest implementation cost. Bloom filters are best for high-risk penetration attacks and very large ID spaces. Logical expiration is ideal for hot data in latency-sensitive scenarios, as long as the business can tolerate short-lived stale reads.
Core takeaways summarize the root causes, impact, and practical solutions.
This article uses a Java + Spring Boot + Redis shop query scenario to systematically reconstruct the causes, risks, and production-grade mitigation strategies for cache penetration, cache breakdown, and cache avalanche. It covers null-value caching, Bloom filters, mutex locks, logical expiration, multi-level caching, prewarming, and cluster-based disaster recovery, while also providing reusable code patterns and practical selection guidance.