This article explains how a Spring AI service can evolve from a single-instance bottleneck into a distributed system capable of handling 10K QPS. It focuses on asynchronous model invocation, decoupling model, vector, and business layers, multi-level caching, and end-to-end observability to solve high latency, thread blocking, and single points of failure. Keywords: Spring AI, distributed architecture, 10K QPS.
Technical Specifications at a Glance
| Parameter | Description |
|---|---|
| Core Language | Java |
| Application Framework | Spring Boot, Spring AI, Spring Cloud |
| Communication Protocols | HTTP/REST, AMQP |
| Vector Retrieval | Milvus, Redis Vector |
| Caching Stack | Caffeine, Redis Cluster |
| Monitoring Components | Prometheus, Grafana, SkyWalking |
| Message Middleware | RabbitMQ |
| Target Metrics | 10K QPS, P95 latency under 500 ms |
The bottlenecks in a single-instance Spring AI architecture are systemic
The original system was a single-instance Spring Boot application responsible for business orchestration, model invocation, and vector retrieval at the same time. It worked when traffic was low in the early stage. But as the business grew, slow model responses, Milvus retrieval jitter, and the risk of instance failure compounded each other, causing overall availability to decline quickly.
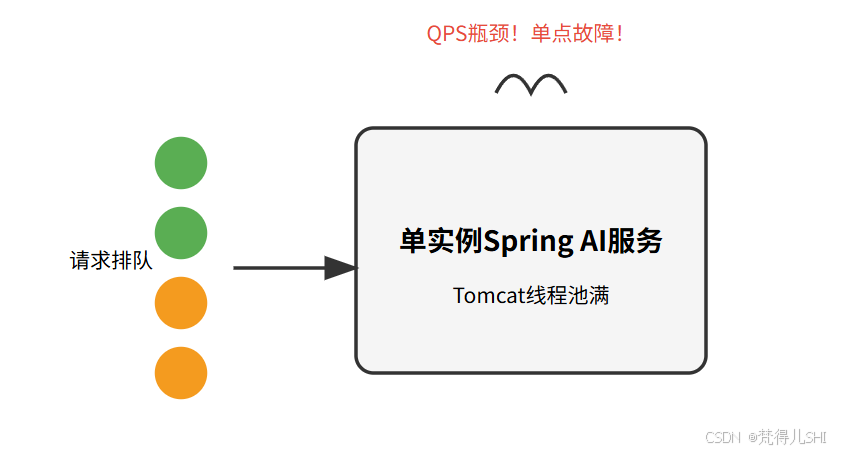 AI Visual Insight: This diagram shows the congestion path of a single-instance AI service: all requests are pushed into the same application node, where model calls, vector retrieval, and business logic share the same threads and resource pools. If any external dependency slows down, the queuing effect is amplified, creating a clear single point of failure.
AI Visual Insight: This diagram shows the congestion path of a single-instance AI service: all requests are pushed into the same application node, where model calls, vector retrieval, and business logic share the same threads and resource pools. If any external dependency slows down, the queuing effect is amplified, creating a clear single point of failure.
The single-instance bottleneck concentrates on three layers
First, synchronous model calls can exhaust Web threads. Second, vector retrieval latency directly slows down the request path. Third, single-node deployment cannot tolerate failures or scaling pressure. For AI services, this is not a parameter-tuning problem. It is a resource-contention problem caused by unclear architectural boundaries.
@Configuration
@EnableAsync
public class AsyncConfig {
@Bean("aiExecutor")
public Executor aiExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
int cpu = Runtime.getRuntime().availableProcessors();
executor.setCorePoolSize(cpu * 2 + 1); // Increase concurrency for IO-intensive tasks
executor.setMaxPoolSize(cpu * 4); // Control peak thread count to avoid excessive switching
executor.setQueueCapacity(500); // Estimate queue capacity based on peak QPS
executor.setKeepAliveSeconds(60);
executor.setThreadNamePrefix("ai-model-");
executor.initialize(); // Initialize the thread pool
return executor;
}
}This code creates a dedicated asynchronous thread pool for model invocation, isolating Web request threads from slow IO operations.
The core goals of distributed evolution must be clearly quantified
This transformation is not about splitting services for its own sake. It is driven by three metrics: support 10K QPS, eliminate single points of failure, and keep main request-path latency consistently below 500 ms. Only with clear goals can thread pools, caches, and service-splitting strategies be optimized in a unified direction.
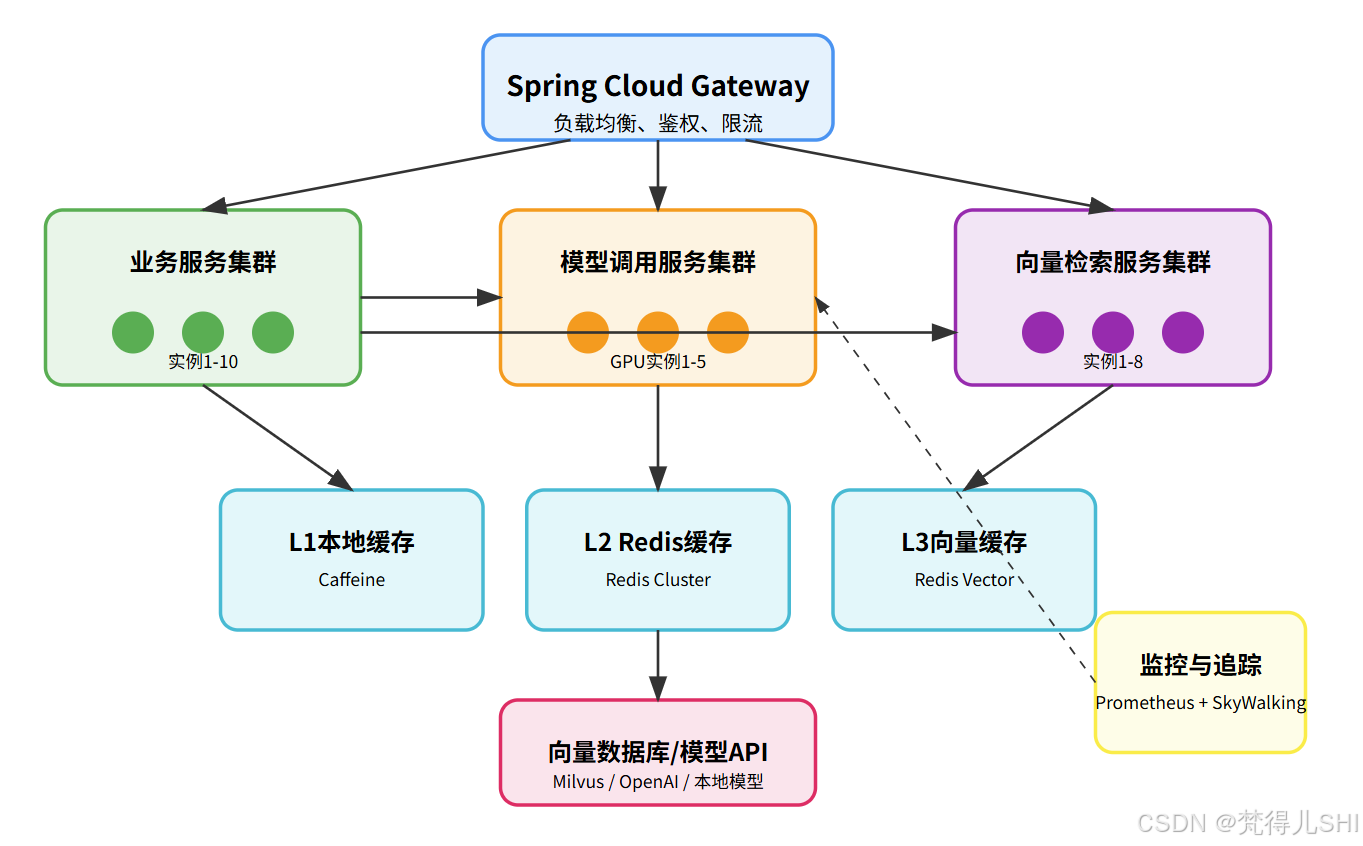 AI Visual Insight: This topology diagram presents a typical five-layer architecture: the gateway layer handles traffic governance, the service layer separates business, model, and vector clusters, the cache layer builds L1/L2/L3 acceleration, the storage layer connects Milvus and model APIs, and the observability layer covers metrics collection and distributed tracing.
AI Visual Insight: This topology diagram presents a typical five-layer architecture: the gateway layer handles traffic governance, the service layer separates business, model, and vector clusters, the cache layer builds L1/L2/L3 acceleration, the storage layer connects Milvus and model APIs, and the observability layer covers metrics collection and distributed tracing.
Service splitting is not microservice formalism but resource decoupling
The business service handles authentication, parameter validation, and result assembly. The model service encapsulates OpenAI or local models behind a unified interface. The vector service focuses on embeddings and similarity retrieval. This allows GPU-oriented nodes, memory-oriented nodes, and general compute nodes to scale independently, avoiding conflicts caused by mixed workloads.
@RestController
@RequestMapping("/business")
public class BusinessController {
@Autowired
private ModelClient modelClient;
@Autowired
private VectorClient vectorClient;
@PostMapping("/qa")
public Result
<String> qa(@RequestBody QaRequest request) {
List
<String> docs = vectorClient.search(request.getQuestion()); // Perform retrieval-augmented lookup first
String answer = modelClient.call(new ModelRequest(request.getQuestion(), docs)).getData(); // Then call the model to generate the answer
return Result.success(answer); // Return a unified response wrapper
}
}This code shows that the business service only orchestrates the workflow and does not directly handle model inference or vector computation.
Asynchrony and batching are the first levers for throughput improvement
AI requests are highly IO-intensive. If the application waits synchronously for the model to return, Tomcat or Netty worker threads remain blocked for long periods. With @Async and a dedicated thread pool, you can move slow calls off the main thread. By adding a batching queue, you can merge multiple requests into a single model call and significantly reduce network overhead.
@Service
public class ModelBatchService {
private final BlockingQueue
<ModelRequest> queue = new LinkedBlockingQueue<>(1000);
public CompletableFuture
<ModelResponse> submit(ModelRequest request) {
CompletableFuture
<ModelResponse> future = new CompletableFuture<>();
request.setFuture(future); // Bind the asynchronous result
queue.offer(request); // Queue the request for later batch processing
return future;
}
}This code shows the entry point for batch request aggregation. It uses a queue to absorb traffic spikes and prepare for downstream batch inference.
Two critical pitfalls in asynchronous request paths must be addressed early
First, ThreadLocal loses context after thread switching. User identity and tenant information must be preserved with TransmittableThreadLocal or explicit context propagation. Second, the thread pool rejection policy must not drop requests directly. It is better to send overflow traffic to a buffering layer such as RabbitMQ for traffic smoothing and backpressure handling.
Multi-level caching is the core infrastructure for controlling AI service cost and latency
AI workloads naturally produce hot questions, hot documents, and hot vectors. If every request hits the model API or vector database, both cost and latency will become unmanageable. A practical design uses Caffeine as the L1 hot cache, Redis Cluster as the shared L2 cache, and Redis Vector as the L3 cache for vector results.
@Service
public class QaService {
public String getAnswer(String question) {
String key = "qa:" + question;
String answer = localCache.getIfPresent(key); // Check the local hot cache first
if (answer != null) return answer;
answer = redisTemplate.opsForValue().get(key); // Then check shared Redis
if (answer != null) {
localCache.put(key, answer); // Backfill the local cache
return answer;
}
return loadAndCache(question); // Only then call the model service
}
}This code demonstrates a typical Cache-Aside read path, which can significantly reduce pressure on both model services and databases.
The stability of the caching system depends on consistency strategy
Use distributed locks to protect hot keys from cache breakdown. Add randomized values to TTLs to prevent cache avalanches. Use Bloom filters to block invalid requests and reduce cache penetration. In AI scenarios, strong consistency requirements are usually lower than in transaction systems, so high hit rates and high availability should take priority.
The complete data flow determines the final user experience
Requests first enter Spring Cloud Gateway, where rate limiting, authentication, and load balancing control ingress traffic. The business service then tries to hit the L1 and L2 caches first. If knowledge augmentation is needed, it calls the vector service to query Redis Vector or Milvus. Finally, when the cache misses, the model service performs batch inference and writes results back into the cache.
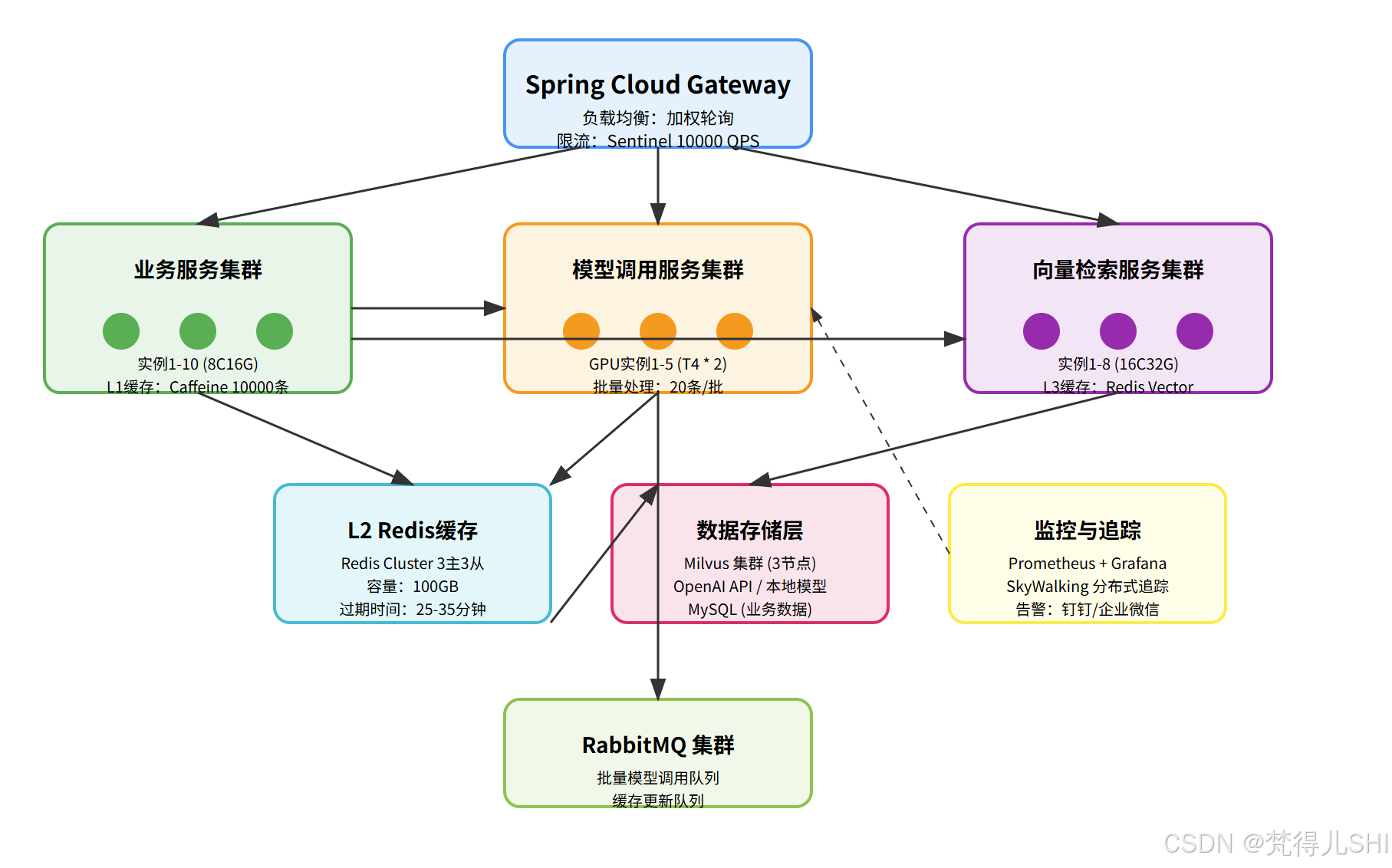 AI Visual Insight: This diagram details how requests move across the gateway, business services, caches, model services, vector databases, and the observability stack. It highlights the combination of front-loaded multi-level caching, asynchronous queue-based traffic smoothing, and multi-cluster horizontal scaling, which forms a typical data path for high-concurrency AI services.
AI Visual Insight: This diagram details how requests move across the gateway, business services, caches, model services, vector databases, and the observability stack. It highlights the combination of front-loaded multi-level caching, asynchronous queue-based traffic smoothing, and multi-cluster horizontal scaling, which forms a typical data path for high-concurrency AI services.
Observability is not optional but a production requirement
Prometheus and Grafana monitor QPS, cache hit ratios, thread pool status, and GPU utilization. SkyWalking provides distributed tracing and helps teams quickly identify whether slowdowns come from the model API, the vector database, or gateway rate limiting. Without observability, scaling and performance tuning become guesswork.
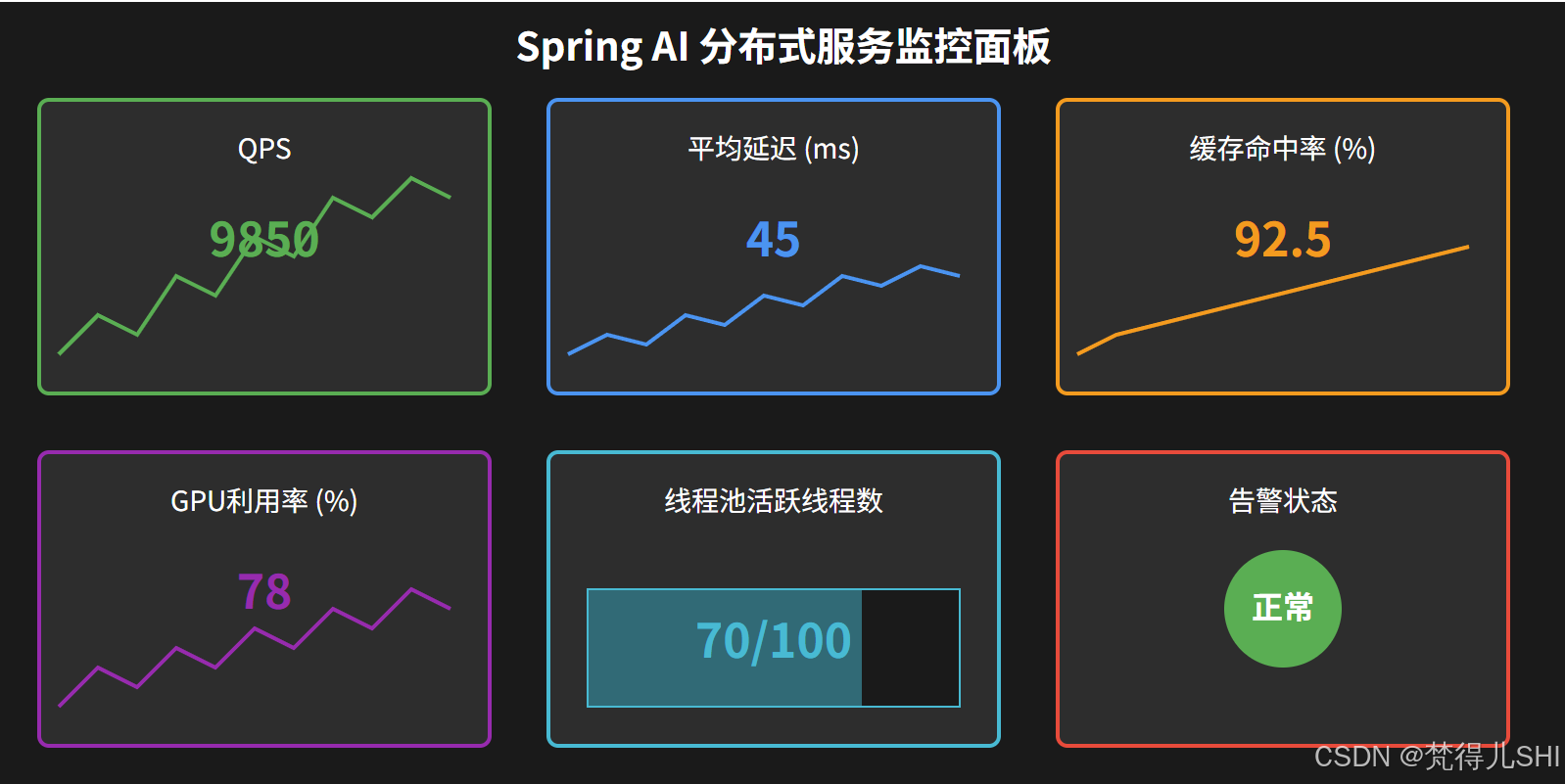 AI Visual Insight: This monitoring screenshot reflects the ability to aggregate multidimensional performance metrics. It typically includes dashboards for request throughput, response time, instance health, and resource utilization, making it suitable for capacity planning, anomaly alerting, and bottleneck diagnosis in AI services.
AI Visual Insight: This monitoring screenshot reflects the ability to aggregate multidimensional performance metrics. It typically includes dashboards for request throughput, response time, instance health, and resource utilization, making it suitable for capacity planning, anomaly alerting, and bottleneck diagnosis in AI services.
@FeignClient(name = "model-service", path = "/model")
public interface ModelClient {
@PostMapping("/call")
Result
<String> call(@RequestBody ModelRequest request); // Use a unified synchronous call to the model service
}This code shows the basic approach to lightweight synchronous communication through Feign after service decomposition.
Production-grade Spring AI architecture optimization should follow a progressive path
Start with asynchronous thread pools and request batching. Then decouple model, vector, and business services. Next, introduce L1/L2/L3 caching. Finally, complete the system with rate limiting, circuit breaking, tracing, and alerting. This incremental path allows the system to evolve from “it runs” to “it withstands load, remains observable, and scales reliably” while keeping risk under control.
FAQ
1. Why does a Spring AI service easily become unresponsive under traffic growth?
Because model invocation and vector retrieval are both slow IO operations. If the system still relies on a synchronous blocking request path, Web threads are quickly exhausted. The key solutions are asynchrony, batching, and thread-pool isolation.
2. Which modules should be split first after decomposing an AI service?
Start with business orchestration, model invocation, and vector retrieval. These three layers have the most different resource requirements, so splitting them yields the clearest scaling benefits and fault-isolation improvements.
3. What is the biggest value of multi-level caching for AI services?
First, it reduces model invocation cost. Second, it lowers latency for high-frequency requests from hundreds of milliseconds to milliseconds. Third, it improves system stability and throughput under peak traffic.
[AI Readability Summary]
This article systematically reconstructs the evolution path of a Spring AI service from a monolith to a distributed architecture. It focuses on asynchronous invocation, thread-pool tuning, service decomposition, multi-level caching, vector retrieval, and observability, helping teams upgrade AI applications with high latency and single points of failure into production-grade architectures capable of supporting 10K QPS.