[AI Readability Summary] This guide explains how to integrate HVI-inspired low-light color representation and the HV_LCA fusion module into the YOLOv11 neck to reduce color distortion, dark-region noise, and weak multi-scale fusion in low-light detection. The main benefits are low-intrusion integration, direct trainability, and strong potential for further customization. Keywords: YOLOv11, HVI, low-light detection
The technical specification snapshot summarizes the implementation scope
| Parameter | Description |
|---|---|
| Task Type | Low-light object detection / Neck enhancement |
| Target Framework | Ultralytics YOLOv11 |
| Primary Language | Python |
| Deep Learning Framework | PyTorch |
| Core Mechanisms | HVI, HV_LCA, CAB, IEL |
| Dependencies | torch, torch.nn, torch.nn.functional, einops, ultralytics |
| Integration Point | Multi-scale feature fusion stage in the neck |
| Reference License | The original page marks it as CC 4.0 BY-SA |
| GitHub Stars | Not provided in the source input |
| Official Code | HVI-CIDNet (GitHub link referenced in the source) |
This is a representation-space enhancement method for low-light detection
The core idea is not to simply stack another attention block into YOLOv11. Instead, it borrows the HVI representation concept from CVPR low-light enhancement research to address intrinsic color-space issues in dark images, then uses HV_LCA to complete cross-layer feature interaction.
It targets three practical pain points: red regions are split across the ends of the HSV hue axis, noise in extremely dark regions is easily amplified, and shallow and deep features are not sufficiently coupled during neck fusion. For low-light object detection, all three directly affect recall and localization stability.
 AI Visual Insight: This figure presents the article’s primary visual and a training-result overview. It emphasizes that the method is designed as a plug-in style integration for the YOLOv11 neck, showing the author’s intent to transfer color-representation ideas from enhancement tasks into the detection-side feature fusion pipeline.
AI Visual Insight: This figure presents the article’s primary visual and a training-result overview. It emphasizes that the method is designed as a plug-in style integration for the YOLOv11 neck, showing the author’s intent to transfer color-representation ideas from enhancement tasks into the detection-side feature fusion pipeline.
HVI delivers its main value by rebuilding color topology
HVI is not a standard convolution block. It is a representation strategy designed to reconstruct color geometry for low-light scenes. It preserves the brightness-decoupling advantage of HSV while fixing HSV’s topological discontinuity around red regions.
In HSV, red appears at both ends of the hue axis, which artificially enlarges Euclidean distance. During enhancement or detection, this often causes red-region fragmentation and artifacts. HVI projects hue onto a continuous plane through polar mapping, so similar colors remain truly close in representation space.
 AI Visual Insight: This overview figure compares sRGB, HSV, and HVI representations and their corresponding enhancement results. The key point is that HVI reduces red artifacts by making hue continuous and improves stability in dark regions.
AI Visual Insight: This overview figure compares sRGB, HSV, and HVI representations and their corresponding enhancement results. The key point is that HVI reduces red artifacts by making hue continuous and improves stability in dark regions.
import torch
def max_rgb_intensity(x):
# Compute the intensity map based on the Max-RGB principle
return torch.max(x, dim=1, keepdim=True).valuesThis code shows the basic source of the intensity component in HVI, which directly extracts a stable upper bound of luminance from the input image.
HVI stabilizes dark-region geometry through a learnable collapse mechanism
Another major challenge in low-light images is that color points near the black plane are loosely distributed, so the network can mistake noise for texture. To address this, HVI introduces a learnable parameter k that performs intensity collapse in low-luminance regions and pulls dark-region color points toward the center.
This gives the network a more compact dark-region representation before enhancement or detection, reducing noise spread. For detection models, that can suppress false background responses, which is especially useful for small objects and targets with blurred edges.
 AI Visual Insight: This figure explains how the HVI color space is constructed. It typically includes hue polarization, saturation modulation, and intensity constraints, showing that HVI does not simply enhance pixels directly. Instead, it reshapes the geometric relationship between color and luminance before features enter the network.
AI Visual Insight: This figure explains how the HVI color space is constructed. It typically includes hue polarization, saturation modulation, and intensity constraints, showing that HVI does not simply enhance pixels directly. Instead, it reshapes the geometric relationship between color and luminance before features enter the network.
HV_LCA provides a lightweight cross-layer fusion module for the neck
In the original implementation, the actual module integrated into YOLOv11 is HV_LCA. It is not the full HVI color transformation itself. Instead, it absorbs the cross-branch interaction ideas from HVI/CIDNet and turns them into a cross-feature fusion layer that fits object detection pipelines.
Its structure can be summarized in three steps: first, use 1×1 convolutions to align input channels; second, apply CAB for cross attention so one branch can extract complementary information from the other; third, use IEL for detail enhancement and nonlinear recalibration.
class HV_LCA(nn.Module):
def __init__(self, channels_in, channels_mid, heads=8, use_bias=False):
super().__init__()
c_a, c_b = channels_in
self.align_a = nn.Identity() if c_a == channels_mid else nn.Conv2d(c_a, channels_mid, 1)
self.align_b = nn.Identity() if c_b == channels_mid else nn.Conv2d(c_b, channels_mid, 1)
def forward(self, feats):
feat_a, feat_b = feats
# Align channels first so later interaction uses the same dimensions
feat_a = self.align_a(feat_a)
feat_b = self.align_b(feat_b)
return feat_a + feat_bThis simplified code captures the first principle of HV_LCA: unify representation dimensions before cross-layer fusion.
CAB and IEL handle information exchange and detail enhancement respectively
CAB stands for Cross Attention Block. It uses q from the current branch and kv from the other branch, so it is not self-attention. It is explicit cross-branch interaction. This design fits the neck well because upsampled features need edge and local texture cues from shallow backbone features.
IEL behaves more like an enhanced feed-forward layer. It uses depthwise separable convolution and Tanh gating to refine local intensity structure, compensating for the fact that attention modules model relationships well but are often weaker at local reconstruction.
attn = (q @ k.transpose(-2, -1)) * temperature
attn = torch.softmax(attn, dim=-1)
out = attn @ v # Aggregate information from the other branch through cross-attentionThese lines form the core of CAB. They determine how features at the current scale selectively absorb information from another scale.
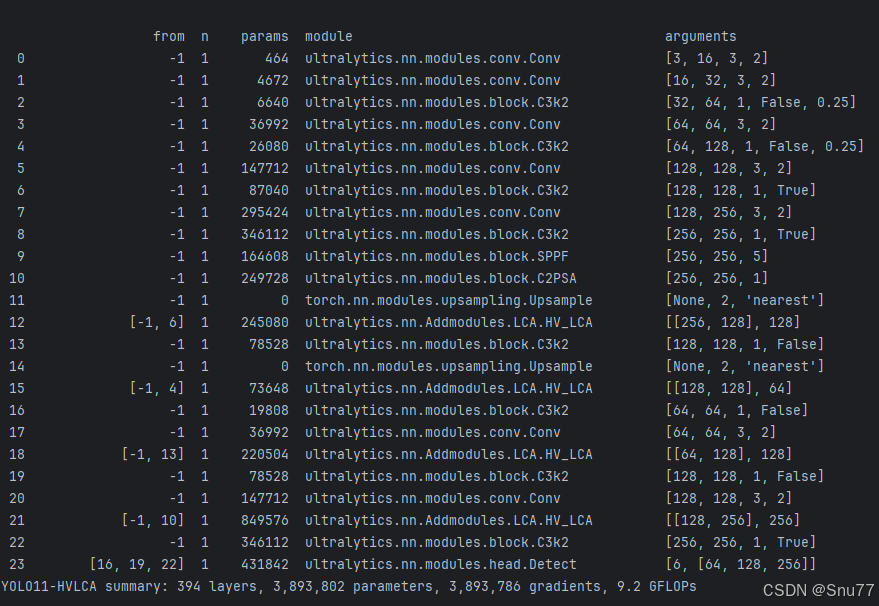
The integration point in YOLOv11 is the neck’s multi-scale aggregation nodes
The original YAML shows that HV_LCA is inserted at three key fusion points: after P4 upsampling and fusion with backbone P4, after P3 upsampling and fusion with backbone P3, and again during the return flow to P4 and P5 for another round of feature interaction.
Compared with a standard concat operation, this layout emphasizes semantic selectivity. Instead of simply concatenating features, it uses learnable relational modeling to decide which low-level details should supplement high-level semantics.
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, HV_LCA, [512]] # Fuse upsampled features with P4 features
- [-1, 2, C3k2, [512, False]]This configuration shows that HV_LCA can directly replace some traditional concat-based fusion nodes and improve the quality of multi-scale information exchange.
The engineering integration workflow can be summarized in four steps
First, create an Addmodules directory under ultralytics/nn and place LayerNorm, CAB, IEL, HV_LCA, and related code into separate files. Second, export the modules in __init__.py. Third, register the modules in tasks.py. Fourth, add a parsing branch in parse_model.
In essence, this allows the Ultralytics model builder to recognize custom layers and instantiate them automatically from YAML. The integration is relatively low-intrusion and works well for iterative experimentation.
The training configuration should prioritize stability and reproducibility
The original training script uses imgsz=640, epochs=150, batch=16, and optimizer='SGD'. If your low-light dataset is small, disable AMP first to avoid numerical instability caused by the combination of attention and normalization.
If you want to verify whether the module truly improves metrics, fix the number of epochs, data split, input size, and augmentation strategy, and replace only the neck structure. Otherwise, the conclusion can easily be polluted by training noise.
from ultralytics import YOLO
model = YOLO("yolo11-HVLCA.yaml") # Load the custom model configuration
model.train(
data="data.yaml", # Point to the dataset configuration
imgsz=640,
epochs=150,
batch=16,
optimizer="SGD",
amp=False # Disable mixed precision if NaN appears
)This training snippet is intended for quickly validating the benefit of the custom neck module on a target dataset.
This enhancement is better suited to specific low-light scenarios
If your task involves nighttime surveillance, low-light security, tunnel inspection, automotive night vision, or underwater weak-light object detection, this type of method is often more effective. That is because it addresses a combined problem: color distortion, dark-region noise, and missing cross-scale detail.
However, if the dataset is well lit, object boundaries are clear, and the scene is simple, this enhancement may not consistently outperform the original YOLOv11. The reason is straightforward: attention and enhancement modules increase modeling complexity, and their gains depend heavily on the data distribution.
The conclusion is that this is fundamentally a combined representation and fusion enhancement
From a technical positioning perspective, this is neither a simple attention-module swap nor a full low-light enhancement pre-processing pipeline. Instead, it abstracts the color-space ideas of HVI into a fusion mechanism suitable for the detection neck. Its value lies in balancing theoretical interpretability, engineering accessibility, and experimental extensibility.
If you want to build low-light detection innovations on top of YOLOv11, this is a strong starting point: first validate the gain from HV_LCA, then continue by adding explicit HVI pre-processing, low-light data augmentation, or loss-based constraints.
FAQ structured answers
Q1: Are HVI and HV_LCA the same module?
No. HVI is primarily a color-space representation method, while HV_LCA is a fusion module implemented for the YOLOv11 neck that absorbs cross-branch interaction and intensity-enhancement ideas from HVI/CIDNet.
Q2: Why does it tend to improve results more easily in low-light scenarios?
Because low-light data often contains color distortion, dark-region noise, and missing edge detail at the same time. HV_LCA supplements detail through cross-layer attention and then strengthens local structure with IEL, which improves detection robustness more effectively.
Q3: What should I do if training becomes unstable or NaN appears after integration?
Disable AMP first, check whether the custom module registration is correct, confirm that input channels are aligned properly, and reduce the initial learning rate. At the same time, fix the random seed and start with a smoke test on a small dataset.
Core summary
This article restructures and distills a practical method for integrating HVI color-space ideas and the HV_LCA feature fusion module into the YOLOv11 neck. It explains how the method mitigates red-region discontinuity, dark-region noise, and insufficient cross-layer fusion in low-light scenes, and it provides core code, YAML configuration, integration steps, and training recommendations.