DeepSeek V4 enters the core open-source LLM race with a 1M-token context window, ultra-low inference cost, and a domestic Ascend-based training pipeline. It targets three persistent pain points: the high cost of long-context inference, unstable large-scale training, and the difficulty of adapting to non-CUDA compute ecosystems. Keywords: DeepSeek V4, 1M-token context, Ascend training.
The technical specification snapshot is already unusually aggressive
| Parameter | Details |
|---|---|
| Project Name | DeepSeek V4 / V4-Pro / V4-Flash |
| Primary Languages | Python, C++ (likely built on a mainstream training stack) |
| Training/Serving Protocols | OpenAI-compatible API, MCP support |
| Model Architecture | MoE (Mixture of Experts) |
| Total Parameters | V4-Pro: approximately 1.6T |
| Active Parameters | Approximately 49B |
| Context Length | 1M tokens |
| Core Dependencies | Transformer, external memory retrieval, CANN, Ascend clusters |
| Open-Source License | Apache 2.0 |
| Popularity Signal | The source material notes strong community attention, but provides no official GitHub star count |
DeepSeek V4 is not a routine iteration but a rewrite of the cost structure
The value of DeepSeek V4 is not only that it is more capable, but that it gets closer to flagship-level performance at a much lower cost. In coding, structured output, and long-context workloads, it attempts to push the capability threshold of closed-source leaders into a more widely deployable range.
 AI Visual Insight: The image presents the release visual for DeepSeek V4, emphasizing launch keywords such as “preview” and “1M context.” It signals that this release is centered on long-context capability and affordable access, rather than simply chasing leaderboard dominance.
AI Visual Insight: The image presents the release visual for DeepSeek V4, emphasizing launch keywords such as “preview” and “1M context.” It signals that this release is centered on long-context capability and affordable access, rather than simply chasing leaderboard dominance.
The preview release strategy reflects engineering reality
V4 shipped as a preview release, which suggests the team prioritized delivering usable capability instead of waiting for every engineering issue to fully converge. Based on the source material, the training process involved Ascend adaptation, server outages, and code rewrites. This looks less like a standard model upgrade and more like an infrastructure-level transition.
model_profile = {
"name": "DeepSeek-V4-Pro",
"context_tokens": 1_000_000,
"pricing": {"input": 0.30, "output": 0.50}, # Unit: USD per million tokens
"traits": ["long context", "high cost efficiency", "domestic compute adaptation"]
}
# Core logic: determine whether this model fits long-document and cost-sensitive scenarios
fit_for_enterprise = (
model_profile["context_tokens"] >= 1_000_000
and model_profile["pricing"]["input"] <= 0.30
)
print(fit_for_enterprise)This snippet provides a quick way to determine whether DeepSeek V4 meets enterprise requirements for long-context processing and cost control.
The dual-model tiering reflects two different product philosophies
V4-Pro targets high-quality, complex workloads, while V4-Flash targets low-cost, high-throughput calls. They are not simply premium and budget variants. Instead, they map to two production paths: quality-first and efficiency-first.
 AI Visual Insight: The image visually highlights the positioning difference between V4-Pro and V4-Flash, typically across dimensions such as performance, task win rate, or price. It reinforces that a lighter model can outperform a flagship variant in selected real-world tasks, which means model selection must be scenario-driven rather than parameter-driven.
AI Visual Insight: The image visually highlights the positioning difference between V4-Pro and V4-Flash, typically across dimensions such as performance, task win rate, or price. It reinforces that a lighter model can outperform a flagship variant in selected real-world tasks, which means model selection must be scenario-driven rather than parameter-driven.
When a cheaper model beats the flagship, the evaluation framework has changed
The source notes that V4-Flash won 7 out of 20 real-world tasks, and exceeded its own Pro variant in 5 of them. That result matters because enterprise buyers no longer optimize only for absolute peak performance. They increasingly optimize for task completion rate per dollar.
Three foundational innovations define the technical core of V4
Engram conditional memory reduces the cost of long-context inference
Traditional Transformer architectures bind knowledge storage and real-time reasoning together, which makes cache usage and computation more expensive as the context grows. Engram conditional memory separates factual storage from the reasoning path through an external retrievable knowledge layer, improving long-context scalability.
The key signal in the source material is that under a 1M-token context, V4-Pro requires only 27% of V3’s per-token inference compute, while KV cache usage drops to just 10% of V3. In practice, that materially lowers deployment costs for long-document QA, codebase understanding, and legal text analysis.
# Simplified illustration: decouple knowledge lookup from generative reasoning
knowledge_base = {"mHC": "stability-enhancing connection mechanism", "Engram": "conditional memory retrieval module"}
query = "Engram"
# Core logic: O(1)-style key-value lookup for external knowledge
fact = knowledge_base.get(query, "unknown concept")
answer = f"The model first retrieves the fact: {fact}, then proceeds to the generative reasoning stage."
print(answer)This example demonstrates the core idea of decoupling external knowledge retrieval from generation.
mHC hyper-connections prioritize training stability first
mHC, or Manifold-Constrained Hyper-Connections, fundamentally controls divergence risk at the network connectivity level. Compared with conventional residual connections, it focuses more directly on gradient stability, loss smoothing, and convergence in large-scale training.
According to the source, mHC delivers roughly a 30% convergence speed improvement and about a 2% gain on coding benchmarks. At trillion-parameter scale, that kind of improvement translates directly into fewer training steps, lower GPU or NPU utilization, and a more manageable training failure rate.
Ascend adaptation means the domestic training stack has entered the main arena
DeepSeek V4 was trained entirely on Huawei Ascend, which is one of the most important industrial signals in this release. The significance is not merely that the model can run on Ascend hardware. It is that the training framework, operator adaptation, and communication optimizations were migrated into the CANN ecosystem.
 AI Visual Insight: The image shows the infrastructure support relationship between Huawei Ascend and DeepSeek V4, typically including supernodes, training platforms, or ecosystem coordination. It indicates that the model no longer depends on a single CUDA path and has completed a large-scale engineering loop on a domestic AI training stack.
AI Visual Insight: The image shows the infrastructure support relationship between Huawei Ascend and DeepSeek V4, typically including supernodes, training platforms, or ecosystem coordination. It indicates that the model no longer depends on a single CUDA path and has completed a large-scale engineering loop on a domestic AI training stack.
Benchmark results show V4 has entered the global top tier in coding
Coding remains DeepSeek’s strongest domain. In the source data, LiveCodeBench reaches 88.4%, SWE-Bench Verified is approximately 73.8%, IMO-AnswerBench reaches 89.8%, and the Codeforces rating is 2441, above 96.3% of human programmers.
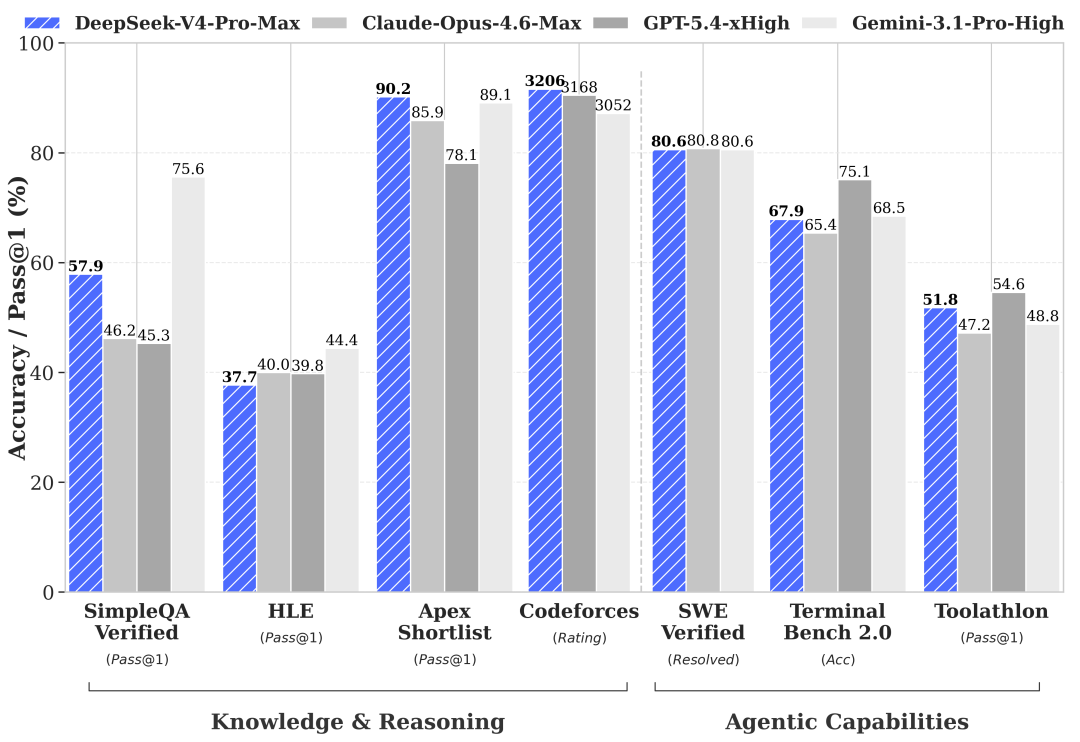 AI Visual Insight: The image focuses on coding benchmarks and shows V4-Pro delivering strong performance in code generation, software repair, and competitive programming. That positioning suggests its target users are not generic chat users, but teams working on software development, agentic coding, and engineering automation.
AI Visual Insight: The image focuses on coding benchmarks and shows V4-Pro delivering strong performance in code generation, software repair, and competitive programming. That positioning suggests its target users are not generic chat users, but teams working on software development, agentic coding, and engineering automation.
Math reasoning approaches closed-source leaders but does not fully surpass them
On benchmarks such as HMMT, GPQA, and MATH-500, V4 comes close to GPT-class performance, but it still leaves a gap. That suggests it is better understood as an engineering-optimal solution than an absolute winner across every dimension.
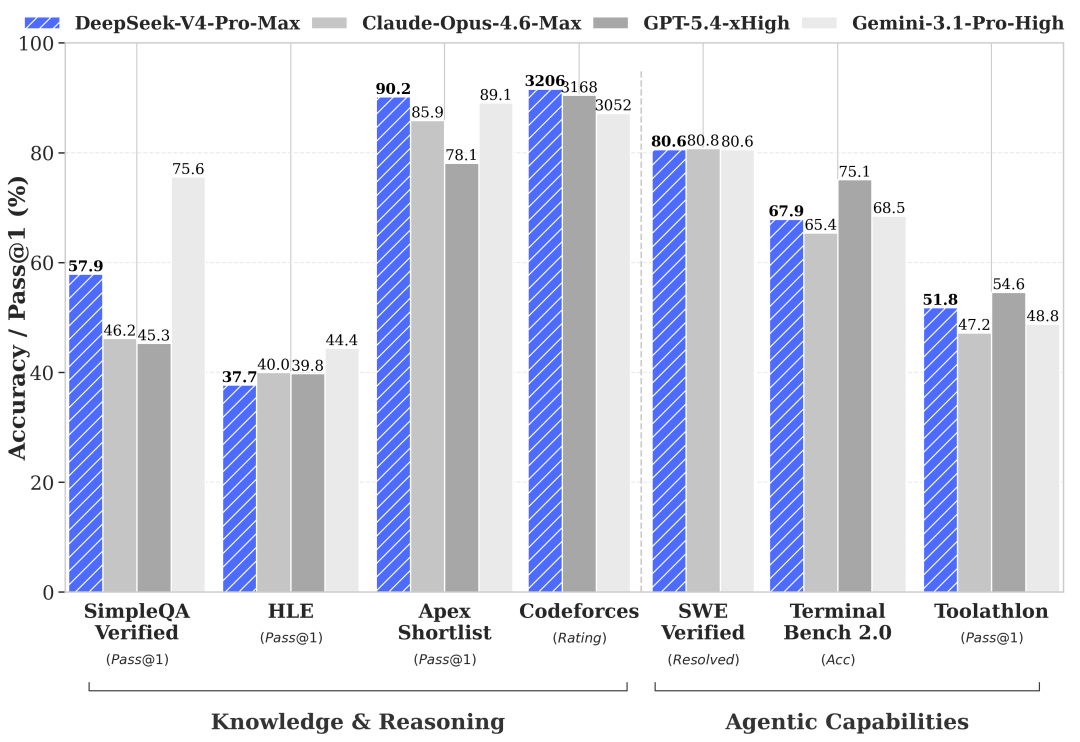 AI Visual Insight: The image compares math and complex reasoning benchmarks, showing that V4 is close to top closed-source models on difficult academic and knowledge-intensive tasks, but still trails in accuracy. It is best viewed as a high-value alternative, not a universal replacement.
AI Visual Insight: The image compares math and complex reasoning benchmarks, showing that V4 is close to top closed-source models on difficult academic and knowledge-intensive tasks, but still trails in accuracy. It is best viewed as a high-value alternative, not a universal replacement.
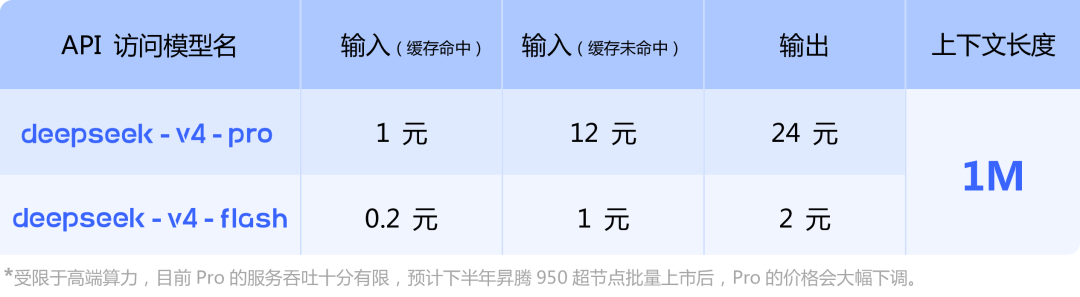
DeepSeek V4 pricing directly changes how developers choose models
V4-Pro costs about $0.30 per million input tokens and about $0.50 per million output tokens, which is significantly lower than GPT-5.4 and Claude Opus 4.6. Under the same budget, developers can allocate more tokens to multi-step agents, long-repository reasoning, and large-scale batch processing.
The best-fit use cases are already clear
- Long-document parsing and knowledge-base question answering
- Agentic coding and automated repair
- Structured tool calling under the MCP protocol
- Enterprise private deployment and Ascend-based infrastructure adaptation
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-v4-pro",
"messages": [
{"role": "system", "content": "You are a coding assistant"},
{"role": "user", "content": "Please summarize the architectural design of this repository"}
]
}'This example shows the basic way to integrate DeepSeek V4 through an OpenAI-compatible interface.
Its weaknesses are also clear and are concentrated at the service layer
The source repeatedly mentions stability issues, including prolonged outages, insufficient throughput during staged rollout, weak performance in Arena-style human preference comparisons, and inconsistent anthropomorphic dialogue quality in the Flash version. In other words, model capability has entered the first tier, but service delivery is still catching up.
The competition with Kimi and GPT is fundamentally a contest between different paths
Compared with Kimi K2.6, DeepSeek V4 leans more toward general capability, ultra-long context, and extreme affordability. Compared with GPT-5.5, it still trails on absolute ceilings such as advanced math reasoning, but it is already highly competitive on cost-performance efficiency.
The practical conclusion for enterprises is straightforward
If your core requirement is the strongest possible single-point capability, closed-source flagships still hold an edge. If your goal is the best scalable overall solution for production deployment, DeepSeek V4 is already very close to becoming the default enterprise choice.
FAQ structured answers clarify where V4 matters most
1. What technical aspects of DeepSeek V4 matter most?
The most important elements are Engram conditional memory, mHC hyper-connections, and Ascend training adaptation. The first two address long-context cost and training stability, while the third determines whether the domestic compute ecosystem can truly support world-class model training.
2. Can DeepSeek V4 directly replace GPT or Claude?
For coding, structured output, long-document processing, and cost-sensitive scenarios, it is a strong candidate for replacement evaluation. For top-end mathematical reasoning and premium preference-aligned conversation quality, you should still benchmark it in parallel against closed-source models.
3. Should developers choose V4-Pro or V4-Flash?
Choose V4-Pro for complex reasoning, core business workflows, and agent orchestration. Choose V4-Flash for bulk summarization, low-cost invocation, and rule-based tasks. The best practice is task-based routing across tiers rather than forcing a single model to handle everything.
AI Readability Summary: This article reconstructs DeepSeek V4 across five dimensions: architecture, training, performance, cost, and production deployment. It focuses on three core innovations—Engram conditional memory, mHC hyper-connections, and Ascend adaptation—while comparing DeepSeek V4 against GPT, Claude, and Kimi in both capability and pricing boundaries.