JiuwenClaw AgentTeam is openJiuwen’s collaboration layer for multi-agent orchestration. Its core value is enabling a Leader and multiple Teammates to deliver complex tasks around shared objectives, a shared workspace, and an event-driven model. This design addresses the limits of a single Agent across full workflows, governance, and recovery. Keywords: Multi-Agent, Coordination Engineering, Event-Driven.
Technical specifications define the system at a glance
| Parameter | Details |
|---|---|
| Project Name | JiuwenClaw AgentTeam |
| Language | Python |
| Collaboration Model | Leader + Teammate |
| Core Protocols / Mechanisms | Event bus, task state transitions, message-driven workflows |
| Default Transport Layer | ZMQ |
| Default Storage Layer | SQLite |
| Replaceable Infrastructure | Pulsar, RocketMQ, PostgreSQL, Redis, and more |
| Core Dependency Capabilities | Harness SDK, Team Workspace, TeamMonitor |
| Open Source Repositories | GitHub / GitCode |
| Stars | Not provided in the source |
JiuwenClaw AgentTeam shifts engineering focus from single-agent execution to team-based delivery
Traditional Agent engineering focuses on prompts, tool invocation, guardrails, and task loops. These capabilities can make an individual Agent usable, but they struggle to cover parallel and interdependent workflows such as research, analysis, writing, review, and consolidation.
AgentTeam effectively upgrades the engineering unit from a “single intelligent agent” to a “governable team of agents.” It emphasizes not just execution, but also task decomposition, role collaboration, process control, and outcome delivery.
 AI Visual Insight: This image presents the conceptual entry point for a multi-agent collaboration product, highlighting the shift from isolated AI capabilities to team-based collaboration in office and knowledge-work scenarios. This typically maps to product patterns such as a unified task panel, layered member roles, and automatic handoff across workflow stages.
AI Visual Insight: This image presents the conceptual entry point for a multi-agent collaboration product, highlighting the shift from isolated AI capabilities to team-based collaboration in office and knowledge-work scenarios. This typically maps to product patterns such as a unified task panel, layered member roles, and automatic handoff across workflow stages.
The smallest coordination unit in AgentTeam is the Leader and Teammate pair
The Leader is responsible for understanding requirements, dynamically assembling the team, creating dependency-aware tasks, and monitoring overall progress. Teammates claim tasks based on their capabilities, execute them independently, and return results.
This structure avoids manual pre-orchestration. The user only describes the goal. The Leader decides who should do what, what should happen first, and when to expand the team or adjust direction, while Teammates remain autonomous within their local tasks.
class TeamFlow:
def run(self, requirement):
leader = LeaderAgent() # The Leader handles global planning
tasks = leader.plan(requirement) # Break the goal into dependency-aware tasks
members = leader.build_team(tasks) # Build the team dynamically based on task capability requirements
for member in members:
member.claim_and_execute(tasks) # Team members autonomously claim and execute tasks
return leader.collect_and_review() # Consolidate results and approve critical outputsThis code summarizes the core AgentTeam workflow as a four-step closed loop: planning, team formation, execution, and consolidation.
Dual-channel coordination through tasks and messages makes the team behave more like a real organization
Many multi-agent systems only support task dispatching and lack mechanisms for discussion, assistance, and negotiation. JiuwenClaw AgentTeam keeps both a task channel and a message channel.
The task channel handles structured progression, such as create, claim, complete, and unblock operations. The message channel handles unstructured collaboration, such as discussing approaches, requesting decisions, reporting anomalies, and adjusting priorities.
 AI Visual Insight: This image highlights the shipped capability entry points of AgentTeam, which usually indicates the system already includes a control plane for team creation, role configuration, task linkage, and execution observability, making it suitable to move from demos toward real business pilots.
AI Visual Insight: This image highlights the shipped capability entry points of AgentTeam, which usually indicates the system already includes a control plane for team creation, role configuration, task linkage, and execution observability, making it suitable to move from demos toward real business pilots.
The event-driven mechanism ensures collaboration does not depend on polling loops
AgentTeam does not rely on the Leader to continuously poll member state. Instead, it normalizes task changes, member status, and message communication into events. Once an event fires, the relevant Agent is awakened immediately.
This also makes dependency release real time. After an upstream task completes, a downstream task can automatically transition from BLOCKED to claimable, reducing manual intervention and wasted waiting time.
def on_task_completed(task_id, bus, board):
board.finish(task_id) # Mark the task as completed
for blocked_task in board.downstream(task_id):
if blocked_task.ready(): # Check whether all dependencies have been satisfied
blocked_task.unblock()
bus.publish("task.unblocked", blocked_task.id) # Broadcast the task-claimable eventThis code shows how the event bus automatically unlocks dependent tasks.
Team Workspace enables multi-agent systems to share artifacts instead of repeating work
One of the hardest problems in multi-agent collaboration is how to share intermediate artifacts. Research findings, analysis tables, chart drafts, and review comments must all be visible, reusable, and conflict-controlled.
Team Workspace addresses this by mounting a team-level shared directory for all members. Each member still retains an individual workspace, but can write cross-member collaboration artifacts into the shared area for immediate reuse by others.
File sharing must solve both consistency and conflict control
Without controls, a shared directory can cause overwrites and dirty data when multiple Agents write to the same file simultaneously. AgentTeam provides file locks, version synchronization, and pre-write checks at the framework layer, removing coordination burdens from prompt design.
In code-oriented scenarios, it can also integrate with Git Worktree to provide isolated filesystem views, allowing “independent development” and “shared outcomes” to coexist.
with workspace.lock("report.md"): # Acquire the shared file lock first
latest = workspace.pull("report.md") # Read the latest version to avoid overwriting
merged = latest + "\nAdditional analysis conclusions" # Merge the current member's new content
workspace.write("report.md", merged)
workspace.commit("update report") # Commit changes and notify other membersThis code demonstrates the basic conflict-safe write flow in the shared workspace.
Full lifecycle governance determines whether the system can enter production
Adding more Agents does not automatically mean the system can deliver results. The real threshold is approval, fault tolerance, recovery, and observability. A key value of JiuwenClaw AgentTeam is that it treats governance as built-in infrastructure.
The first example is approval. Teammates can submit a Plan for Leader review before execution. High-risk tool calls can also go through tool approval. This keeps critical decision authority at the upper layer rather than delegating everything to execution agents.
Self-healing and observability keep the team operating under failure conditions
The system tracks issues such as unclaimed tasks, execution timeouts, unexpected member disconnects, and missed messages. It reduces deadlock risk through heartbeat detection, automatic restarts, and polling fallback.
TeamMonitor provides query APIs and event-stream subscription capabilities, making it easier for external systems to build dashboards, audit logs, and automation workflows.
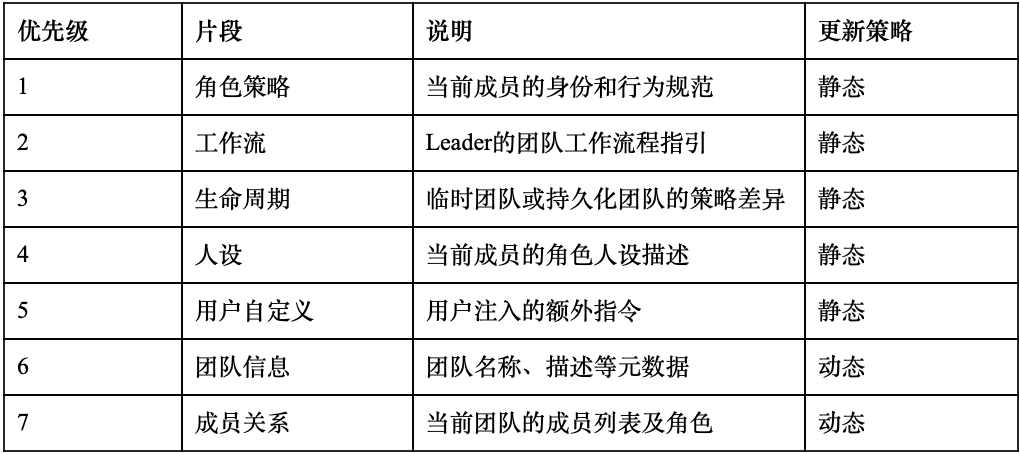 AI Visual Insight: This image shows a segmented prompt injection structure, indicating that team context is not assembled as one oversized prompt. Instead, it is organized into modular sections such as role strategy, team metadata, and member relationships, with caching used to reduce repeated prompt construction overhead.
AI Visual Insight: This image shows a segmented prompt injection structure, indicating that team context is not assembled as one oversized prompt. Instead, it is organized into modular sections such as role strategy, team metadata, and member relationships, with caching used to reduce repeated prompt construction overhead.
The core openJiuwen AgentTeam architecture emphasizes layering and pluggability
The first layer is a unified TeamAgent abstraction. The Leader and Teammate share the same base class, but switch toolsets, prompt strategies, and event-handling logic according to role.
The second layer is CoordinatorLoop. It receives both real-time events and polling events, then converts tasks, messages, and member state into the next Agent action through scheduling. This balances low latency with eventual consistency.
Segmented prompts and replaceable infrastructure improve engineering extensibility
TeamRail splits team context into multiple sections. Static sections initialize once, while dynamic sections refresh based on timestamps. This reduces prompt assembly cost before model calls and makes it easier to extend the system with additional context modules later.
The communication and storage layers are also pluggable. The default stack uses ZMQ and SQLite, while distributed deployments can switch to Pulsar, RocketMQ, PostgreSQL, and similar systems.
 AI Visual Insight: This image illustrates a pluggable communication-layer architecture. The core idea is that TeamAgent is decoupled from the underlying message middleware: lightweight transport works for single-node setups, while distributed scenarios can swap in enterprise-grade message queues for higher reliability and scalability.
AI Visual Insight: This image illustrates a pluggable communication-layer architecture. The core idea is that TeamAgent is decoupled from the underlying message middleware: lightweight transport works for single-node setups, while distributed scenarios can swap in enterprise-grade message queues for higher reliability and scalability.
 AI Visual Insight: This image shows a replaceable storage-layer design, indicating that task state, member information, and persistence configuration are not bound to a single database. Through a unified abstraction, the framework supports smooth migration from local development storage to production databases.
AI Visual Insight: This image shows a replaceable storage-layer design, indicating that task state, member information, and persistence configuration are not bound to a single database. Through a unified abstraction, the framework supports smooth migration from local development storage to production databases.
Coordination Engineering is the next step for multi-agent systems
The architecture described here shows that JiuwenClaw AgentTeam is not about “adding a few more Agents.” Its focus is to turn team organization, state consistency, approval governance, self-healing recovery, and observability into system-level capabilities.
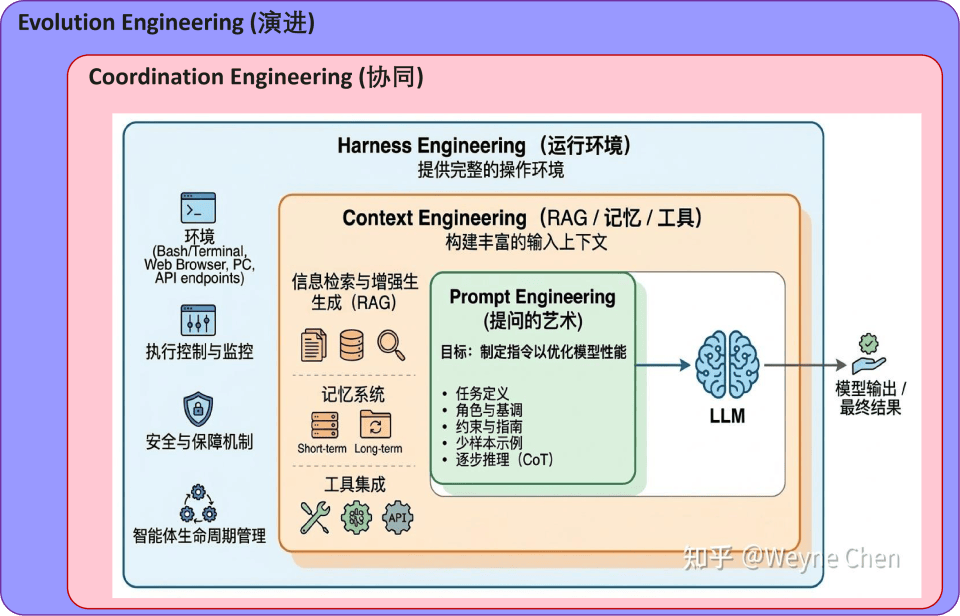
That means multi-agent engineering is evolving from Harness Engineering to Coordination Engineering. The former closes the capability loop for a single Agent, while the latter solves how multiple Agents can complete real-world delivery in a stable, controllable, and auditable way.
For enterprise scenarios, this upgrade is especially important. Businesses do not need Agents that can merely chat. They need collaborative systems that can decompose tasks in parallel, share artifacts, handle failures, and leave behind an audit trail.
FAQ provides structured answers for practical adoption
1. What is the biggest difference between JiuwenClaw AgentTeam and traditional multi-agent orchestration frameworks?
The biggest difference is that it treats collaborative governance as a built-in framework capability rather than simply providing a runtime container for multiple Agents. Its core strengths are the Leader/Teammate hierarchy, dual task-and-message channels, a shared workspace, approval mechanisms, and self-healing event-driven execution.
2. Why is Team Workspace a critical component for real-world multi-agent deployment?
Because the real value of multi-agent collaboration comes from reusing intermediate artifacts. Without a shared workspace, members can only pass file paths through messages or regenerate outputs repeatedly, which makes stable team productivity difficult. Workspace improves consistency through a shared directory, locking, and version synchronization.
3. Which scenarios are the best early candidates for this architecture?
It is best suited for scenarios with long workflows, multiple roles, and clear task dependencies, such as industry research report generation, collaborative software development, knowledge organization, office workflow automation, and enterprise-grade agent orchestration. These use cases show the benefits of coordination engineering over a single-Agent design most clearly.
Core summary
This article systematically breaks down the coordination engineering design of JiuwenClaw AgentTeam: Leader/Teammate role separation, event-driven scheduling, shared workspace, approval and self-healing, persistence and observability, and a pluggable communication and storage architecture. Together, these elements show how multi-agent systems can evolve from “able to run” to “able to deliver reliably at steady state.”