GPT-5.5 is OpenAI’s next-generation model for agentic workflows. Its core improvements focus on coding, multi-tool coordination, knowledge processing, and scientific analysis—addressing persistent issues such as weak planning for complex tasks, fragile long-horizon execution, and unstable tool use. Keywords: GPT-5.5, agentic coding, long context.
The technical specification snapshot highlights the model’s positioning
| Parameter | Details |
|---|---|
| Model | GPT-5.5 / GPT-5.5 Pro |
| Primary use cases | Agentic coding, knowledge work, scientific research, computer use |
| Context window | Codex 400K, up to 1M via API |
| API pricing | gpt-5.5: $5 per million input tokens, $30 per million output tokens |
| Pro pricing | $30 per million input tokens, $180 per million output tokens |
| Serving infrastructure | NVIDIA GB200 / GB300 NVL72 |
| Core capabilities | Tool use, long-range reasoning, browsing, code generation, computer use |
| Core dependencies | Codex, Responses API, Chat Completions API |
| Representative benchmarks | Terminal-Bench 2.0, GDPval, OSWorld, FrontierMath, CyberGym |
| GitHub stars | Not provided in the source content |
GPT-5.5 has evolved from a chat model into an agentic model that can execute work
The key change in GPT-5.5 is not just higher benchmark scores. It is the stronger ability to complete tasks reliably over time. The model can handle ambiguous requirements, automatically plan steps, execute across tools, and continue after checking intermediate results.
This means developers can hand off multi-stage tasks—such as refactoring, debugging, research, documentation cleanup, and spreadsheet analysis—to the model as a whole instead of manually decomposing them turn by turn. Compared with traditional Q&A-style models, GPT-5.5 behaves more like an execution system that can deliver outcomes.
Its core capability can be abstracted into a four-stage workflow
# Define a typical agentic work loop
workflow = [
"Understand the goal", # Identify the real intent instead of matching the surface prompt
"Create a plan", # Break the task into subtasks and dependencies
"Call tools", # Use code, browser, terminal, or document tools to execute
"Validate results" # Check outputs and continue refining
]
for step in workflow:
print(step) # Advance the complex task step by stepThis code captures the execution loop that GPT-5.5 emphasizes.
GPT-5.5’s improvements in agentic coding offer the most immediate practical value
In software engineering, GPT-5.5 stands out in complex engineering tasks rather than single-function completion. It performs better at maintaining long context, editing across files, locating issues, validating hypotheses, and propagating fixes into related modules.
In public results, Terminal-Bench 2.0 reaches 82.7%, up from GPT-5.4’s 75.1%. OpenAI’s internal Expert-SWE evaluation reports 73.1%, also ahead of the previous generation. On SWE-Bench Pro, it reaches 58.6%, indicating stronger end-to-end issue resolution in real-world bug-fixing workflows.
The core of coding capability is not writing faster, but changing code correctly
# A typical agentic coding task chain
git checkout -b fix/comment-system
npm test # Run tests first to locate failures
npm run lint # Check style and potential errors
npm run build # Verify the build pipeline end to endThis kind of task chain reflects the engineering pattern GPT-5.5 handles well: plan, execute, and validate.
The benchmark curve in the image shows simultaneous gains in intelligence and cost efficiency
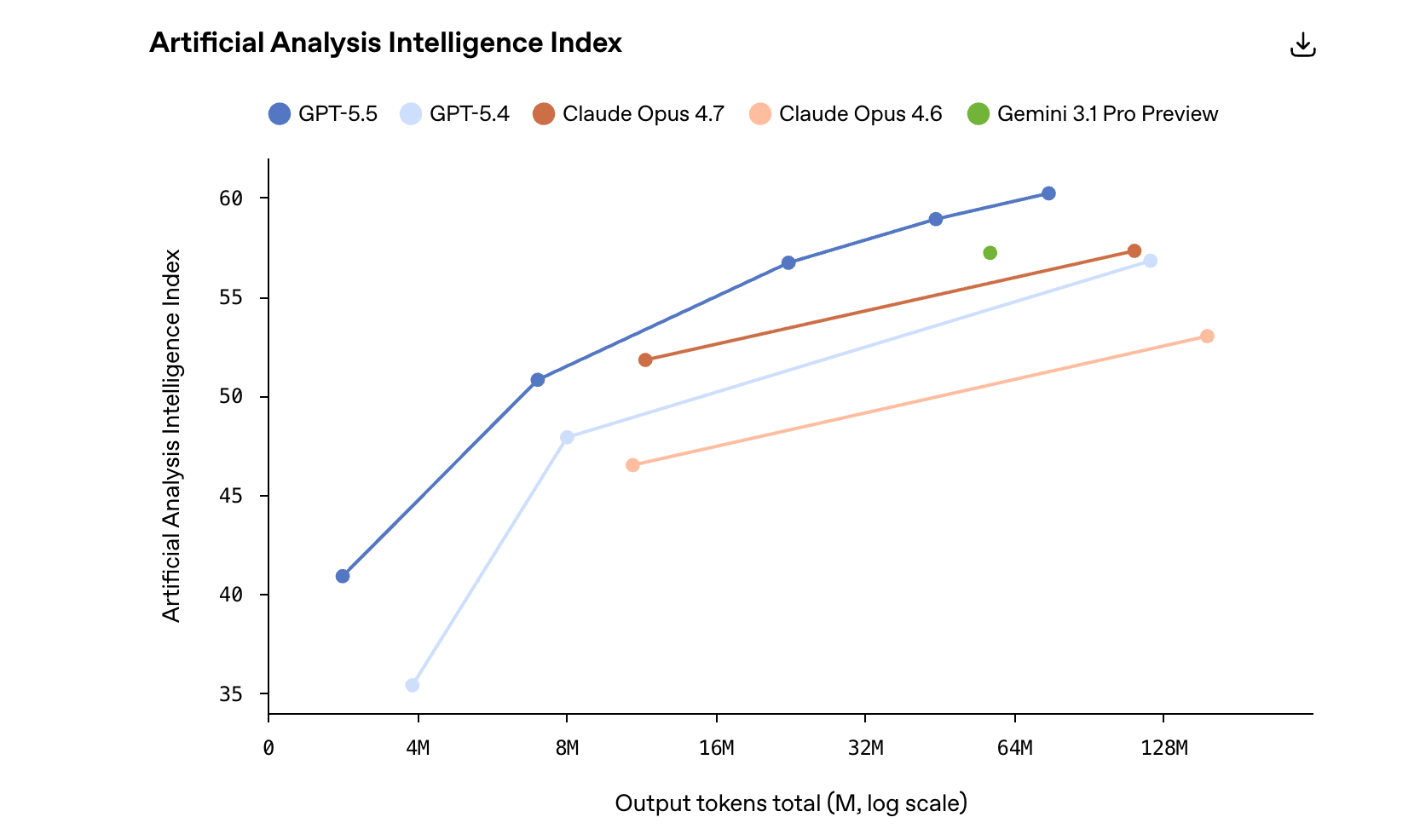 AI Visual Insight: The chart shows GPT-5.5’s position on an external composite intelligence index. It highlights that the model achieves higher overall capability after weighting multiple benchmarks while also maintaining better cost efficiency. Curves like this typically show that a model does not lead on only a single benchmark, but instead improves in a balanced way across coding, academic reasoning, tool use, and knowledge processing.
AI Visual Insight: The chart shows GPT-5.5’s position on an external composite intelligence index. It highlights that the model achieves higher overall capability after weighting multiple benchmarks while also maintaining better cost efficiency. Curves like this typically show that a model does not lead on only a single benchmark, but instead improves in a balanced way across coding, academic reasoning, tool use, and knowledge processing.
This figure corresponds to the Artificial Analysis Intelligence Index. Its value lies in reducing the bias of any single leaderboard through weighted averaging across multiple evaluations, which makes it a better proxy for real-world overall capability. For decision-makers, this is more useful than looking at only one math or coding score.
GPT-5.5 is redefining the boundary of knowledge work automation
GPT-5.5 does more than answer questions. It can complete a full loop of finding information, extracting the key points, generating structured output, and validating the result. OpenAI’s examples span finance, marketing, communications, data science, and product management.
Representative metrics include GDPval at 84.9%, OSWorld-Verified at 78.7%, and Tau2-bench Telecom at 98.0%. These results suggest that the model can do more than generate content—it can complete tasks inside real software interfaces and multi-tool environments.
A task template for knowledge work can be designed like this
{
"goal": "Analyze six months of business request data and produce a risk-tiering report",
"steps": ["Read the data", "Identify patterns", "Generate a scoring framework", "Output conclusions"],
"checks": ["Outlier validation", "Field completeness check", "Conclusion interpretability"]
}This template shows that high-quality knowledge work depends on structured goals, execution steps, and result validation.
GPT-5.5 matters in scientific research because it turns reasoning into an engine for experimentation
Compared with earlier models, GPT-5.5 is better suited to the multi-stage loops common in research: propose a hypothesis, read data, identify anomalies, revise the method, interpret the result, and continue into the next experiment.
In academic evaluations, GeneBench rises from 19.0% to 25.0%, BixBench reaches 80.5%, and FrontierMath Tier 4 reaches 35.4%. Together, these results show that its support for research is no longer limited to explaining papers. It is moving closer to acting as a collaborative research partner.
The minimum executable skeleton for a research workflow often looks like this
def research_loop(question, data):
hypothesis = f"Hypothesis to validate: {question}" # Generate a hypothesis from the question
evidence = analyze(data) # Analyze the data
result = interpret(evidence) # Interpret the analysis result
return result # Return an intermediate conclusion for further discussionThis pseudocode reflects GPT-5.5’s core value in research: sustained progress rather than one-shot answers.
Long context and reasoning efficiency make it more suitable for real production environments
GPT-5.5 shows clear improvement at a 1M-token context length. On Graphwalks BFS 1mil F1, it reaches 45.4%, far above GPT-5.4’s 9.4%. OpenAI MRCR v2 evaluations across multiple segment ranges also indicate more stable retrieval in ultra-long-context settings.
At the same time, OpenAI emphasizes that its service latency is close to GPT-5.4 while delivering higher intelligence and more efficient token usage. That matters for enterprises because real cost is not determined by unit pricing alone. It also depends on how many interaction rounds and how many wasted tokens are required to complete a task.
Cybersecurity and safety strategy are a central part of the GPT-5.5 release
GPT-5.5’s cybersecurity capability is rated High. OpenAI also strengthened classifiers, abuse monitoring, Trusted Access for Cyber, and collaboration mechanisms with critical infrastructure partners as part of the release. This indicates that model capability gains and safety investment are progressing in parallel.
In evaluation results, CyberGym reaches 81.8%, and internal CTF tasks score 88.1%. For developers, this means the model is better suited to security analysis, vulnerability understanding, and defensive assistance. It also means the API and platform will likely enforce stricter access and usage boundaries.
Example constraints for security-oriented requests
def allow_request(user, task):
if user != "verified" and task == "high_risk_cyber":
return False # High-risk cyber tasks require stricter trust verification
return TrueThis code expresses the core logic behind GPT-5.5’s safety release strategy: capability access and risk control coexist.
Availability and pricing suggest the target users are teams executing high-value tasks
GPT-5.5 is currently rolling out across ChatGPT and Codex for Plus, Pro, Business, and Enterprise users, with the API version following afterward. Codex offers a 400K context window, while the API supports up to 1M context.
From a pricing standpoint, gpt-5.5 sits in the upper-mid to premium tier. But if it can complete complex tasks with fewer retries and fewer tokens, the total cost may not exceed that of cheaper models that require repeated rework. For engineering teams, the metric that matters is the cost per successful delivery.
FAQ provides structured guidance for practical adoption
What is the most important improvement in GPT-5.5 for developers?
The most important change is stronger agentic execution: better long-horizon planning, stronger cross-tool collaboration, improved context retention, and more reliable result validation. It no longer just generates answers—it behaves more like a system that completes tasks.
Can GPT-5.5 directly replace an existing coding assistant?
It is well suited for complex refactoring, cross-file edits, debugging, and validation. However, teams should still connect it to testing, CI, and human review workflows. Use it as a highly autonomous engineering assistant, not as a fully unsupervised release system.
How should teams choose between GPT-5.5 and GPT-5.5 Pro?
Choose GPT-5.5 first for standard engineering, knowledge work, and automation tasks. Choose GPT-5.5 Pro when the task requires higher accuracy, deeper reasoning, and more complex analysis, while accepting the higher cost.
The core summary helps developers evaluate real deployment value quickly
This article reconstructs the GPT-5.5 release information with a focus on its major improvements in agentic coding, knowledge work, scientific research, long context, and cybersecurity. It also organizes the key benchmarks, pricing, availability, and infrastructure upgrades to help developers quickly assess its real-world adoption value.