Graphify builds a codebase knowledge graph once, persists relationships among functions, classes, documents, and multimedia to local storage, and answers future queries through graph traversal instead of repeatedly reading source files. It addresses the high token cost of large repositories and the inability of vector retrieval to express structural relationships well. Keywords: Knowledge Graph, Code Retrieval, GraphRAG.
The technical specification snapshot is straightforward
| Parameter | Details |
|---|---|
| Language | Python 3.10+ |
| Core Protocols / Interfaces | CLI, MCP Server, direct AI API integration |
| GitHub Stars | Not provided in the original source |
| Core Dependencies | tree-sitter, faster-whisper, vis.js, Leiden, JSON |
| Input Types | Code, Markdown, PDF, RST, images, audio, video |
| Output Types | HTML graph, JSON graph, Markdown report, Neo4j, GraphML, SVG |
Graphify replaces similarity retrieval with an explicit graph
Graphify’s core idea is not chunking and embedding. Instead, it performs a full analysis first, then compresses the repository into a queryable graph. Nodes can represent functions, classes, modules, or document sections. Edges represent calls, imports, references, and inferred dependencies.
Compared with traditional RAG systems that depend on top-K similar chunks, Graphify is better suited for structural questions such as “who calls whom” or “how a specific path flows through the system.” Those facts live naturally in call graphs and dependency graphs, not in vector space.
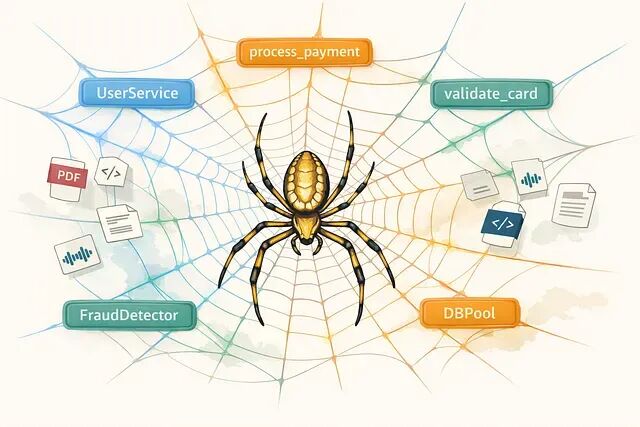 AI Visual Insight: This diagram shows Graphify’s end-to-end process for mapping multi-source repository content into a unified knowledge graph. It highlights the architecture principle of “preprocess once, query many times,” showing that queries no longer need to reread raw files and can instead access a persisted network of entities and relationships directly.
AI Visual Insight: This diagram shows Graphify’s end-to-end process for mapping multi-source repository content into a unified knowledge graph. It highlights the architecture principle of “preprocess once, query many times,” showing that queries no longer need to reread raw files and can instead access a persisted network of entities and relationships directly.
# Run standard graph analysis on the current repository
/graphify
# Query the existing graph only, without rescanning source code
/graphify query "how does user authentication flow through the system?"These commands illustrate Graphify’s two-phase model: build the graph first, then run low-cost queries against it.
The real cost of large codebases is context tax
A larger context window does not mean the retrieval problem disappears. In repositories with hundreds of files, if every query pushes large volumes of source code into the model, context cost, latency, and noise all increase together.
Graphify tries to move the scanning cost upfront. The initial import is heavier, but later queries only need to traverse a small number of nodes and edges, which is theoretically a better fit for high-frequency analysis scenarios.
Graphify uses a three-stage processing pipeline
Graphify does not apply the same logic to every file type. Instead, it splits processing into three passes based on content type. This design is one of the key differences between Graphify and lightweight RAG tools.
Pass 1 uses ASTs for deterministic code extraction
Graphify sends source code to tree-sitter for parsing and directly generates explicit structures such as functions, classes, imports, and call relationships. This process requires no model participation and makes no network calls, so the code never leaves the local machine.
The value of this step is low cost and high precision. Any relationship derived directly from the AST is labeled EXTRACTED, which means it is a fact rather than a guess.
from tree_sitter import Language, Parser
parser = Parser()
# Assume the target language grammar has already been loaded here
parser.set_language(Language("build/lang.so", "python"))
source = b"def process_payment():\n validate_card()"
tree = parser.parse(source) # Parse the source code into an ASTThis snippet shows that Graphify’s deterministic foundation comes from syntax trees, not semantic similarity.
Pass 2 performs local audio and video transcription
If the repository contains meeting recordings or demo videos, Graphify can optionally enable faster-whisper for local transcription. The generated text is merged into the graph and becomes a set of document nodes that can be searched and linked.
This allows spoken knowledge from code reviews and architecture discussions to become part of the engineering knowledge surface without requiring teams to manually write meeting notes.
# Install video and audio processing support
pip install "graphifyy"This dependency enables local transcription and avoids uploading audio to a third-party relay service.
Pass 3 uses AI APIs to extract semantics from documents and images
Markdown, PDF, RST, and images cannot be parsed through ASTs like source code, so Graphify calls developer-configured AI APIs to extract entities and relationships from those assets.
One important detail is that Graphify does not host credentials or forward traffic through a central service. However, your documents and images are sent directly to the selected model provider, so sensitive environments should enable this mode with caution.
 AI Visual Insight: This figure highlights the result of Graphify’s community detection on a large repository. Different color regions represent distinct module clusters, while bridge nodes reveal cross-domain dependencies. This makes it much easier to spot boundaries and coupling hotspots across areas such as auth, billing, and infrastructure.
AI Visual Insight: This figure highlights the result of Graphify’s community detection on a large repository. Different color regions represent distinct module clusters, while bridge nodes reveal cross-domain dependencies. This makes it much easier to spot boundaries and coupling hotspots across areas such as auth, billing, and infrastructure.
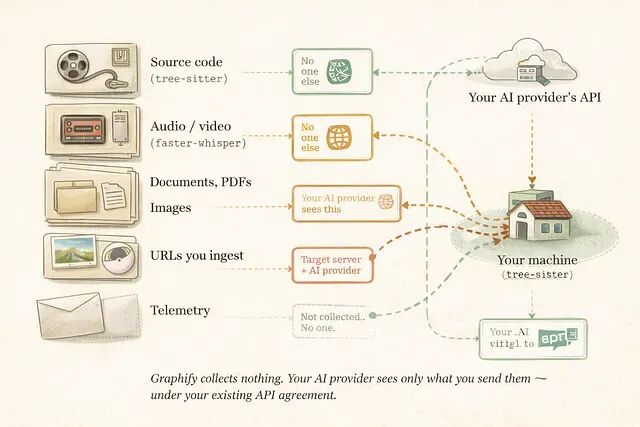 AI Visual Insight: This diagram shows the complete data flow from code, documents, images, audio, and video into graph persistence and query outputs. It emphasizes that different media types enter different processing passes and ultimately converge into a unified graph model, while also marking the boundary between local processing and external AI API calls.
AI Visual Insight: This diagram shows the complete data flow from code, documents, images, audio, and video into graph persistence and query outputs. It emphasizes that different media types enter different processing passes and ultimately converge into a unified graph model, while also marking the boundary between local processing and external AI API calls.
Confidence labels keep the graph useful without making it overconfident
Graphify assigns one of three labels to each edge: EXTRACTED, INFERRED, or AMBIGUOUS. These labels are not cosmetic. They define the practical usage boundary of the graph.
EXTRACTED can be treated as an engineering fact. INFERRED works better as an exploratory clue. AMBIGUOUS is closer to a prompt for manual review. Compared with flattening all relationships into a single version of truth, this layered design is better suited to production-grade assisted analysis.
# Deep mode produces more aggressive relationship inference
/graphify --deep
# Query the shortest path between two entities
/graphify path "UserService" "DatabasePool"These commands show that Graphify answers not only “what is there,” but also “how things connect” through path analysis.
Graphify is a better fit for stable and complex mixed repositories
It is especially useful for projects that combine code, architecture documents, PDFs, and meeting recordings. It also fits teams that ask repeated questions against the same repository, because incremental updates and caching continue to increase the return on the initial indexing cost.
The original source claims that Graphify can reduce per-query token usage by 71.5x on mixed corpora. That figure still needs independent benchmarking, but the architectural direction of “model upfront, traverse later” makes the benefit plausible.
Current limitations mean it is not a universal replacement
If a repository contains only a dozen files, the upfront cost of graph construction may not be worth it. If the main task is open-ended semantic Q&A, traditional RAG may still be more direct.
In addition, Graphify is currently an individual open-source project. Its release cycle is fast, but its long-term maintainability still needs to be observed. Another practical detail is that the tool name is graphify, while the PyPI package name is graphifyy, which requires extra attention during installation.
# Install the main package
pip install graphifyy
# Register it with your AI platform
graphify installThese two steps complete the base installation and inject the corresponding skill into environments such as Claude Code.
FAQ answers the most common implementation questions
Will Graphify replace vector retrieval?
No. It is better understood as an enhanced approach for code structure understanding scenarios. For call chains, module dependencies, and multi-hop path questions, graph traversal usually outperforms pure vector retrieval. But that does not automatically make it better for open-ended semantic search.
Is Graphify suitable for sensitive code repositories?
If you enable only Pass 1, source code parsing can run entirely locally, which offers stronger security. If you enable Pass 3, documents and images will be sent to your configured AI provider, so you should review that provider’s data handling policies carefully.
What is Graphify’s biggest value?
Its biggest value is not simply that it can build a graph. The real value is that it converts one expensive analysis step into continuous low-cost querying. For large and stable repositories, this can significantly improve the context efficiency and structural understanding of AI coding assistants.
The core summary is clear
Graphify is a Python-based codebase knowledge graph tool that uses AST extraction, local transcription, and semantic extraction to compress code, documents, and multimedia into a queryable graph. It replaces vector retrieval with graph traversal to reduce large-model query cost and strengthen structured understanding.