For Industrial IoT and big data platforms, this article reframes the core logic of time-series database selection: start with write scale, query patterns, and scaling strategy, then evaluate whether you need edge deployment and ecosystem integration. It focuses on Apache IoTDB’s hierarchical model, TsFile, native distributed architecture, and edge-cloud collaboration. Keywords: time-series database, Apache IoTDB, database selection.
Technical Specification Snapshot
| Parameter | Details |
|---|---|
| Domain | Time-series database selection and architecture evolution |
| Representative Solutions | InfluxDB, TimescaleDB, Prometheus, Apache IoTDB |
| Core Languages / Interfaces | SQL, Flux, PromQL, Java SDK |
| Key Protocols / Access Methods | JDBC, REST API, MQTT, OPC-UA |
| Core Dependencies | PostgreSQL, TsFile, SessionPool, Spark Connector |
| Deployment Modes | Standalone, cluster, edge node, edge-cloud collaboration |
| GitHub Stars | Not provided in the source content; this article makes no assumptions |
Time-series database selection starts with architecture, not products
A time-series database is not simply any database that can store timestamped data. At its core, it is a database system specifically optimized for high-frequency writes, time-based queries, tiered storage, and aggregation analytics.
In scenarios such as Industrial IoT, device monitoring, connected vehicles, and observability, the real challenge is usually not whether the feature set is sufficient. The challenge is whether throughput, compression, query performance, and scalability can all hold up at the same time. That is why selection must begin with architectural paradigms.
Core challenges
- Write throughput: Can it handle concurrent ingestion from millions of data points reliably?
- Storage cost: Can it compress terabyte-scale daily data growth effectively?
- Query efficiency: Can it process window aggregations and cross-device scans efficiently?
- Cluster scaling: Does it support sharding, replication, and migration natively?
- Edge-cloud collaboration: Can it support smooth edge autonomy and cloud aggregation?This checklist defines the five most important technical dimensions in time-series database selection.
The architectural differences among mainstream solutions define their practical boundaries
InfluxDB uses its self-developed TSM engine and is oriented toward high-throughput ingestion. TimescaleDB builds on the PostgreSQL ecosystem and emphasizes SQL compatibility and ecosystem completeness. Prometheus is better suited for monitoring metric collection and querying. Apache IoTDB is clearly designed for Industrial IoT and device-centric hierarchical scenarios.
From the perspective of the data model, IoTDB stands out. Instead of forcing device dimensions into tags or relational tables, it directly expresses device topology through hierarchical paths. This maps naturally to factories, production lines, workshops, devices, and measurement points.
Comparing architectural paradigms quickly narrows the candidate set
| Dimension | InfluxDB | TimescaleDB | Prometheus | Apache IoTDB |
|---|---|---|---|---|
| Storage Engine | TSM | PostgreSQL extension | Custom storage | TsFile |
| Data Model | Line Protocol | Relational tables | Metric-label | Hierarchical tree structure |
| Query Language | Flux / InfluxQL | SQL | PromQL | SQL-compatible |
| Cluster Capability | Stronger in Enterprise edition | Depends on the PostgreSQL stack | Federated query | Native distributed architecture |
| Edge Deployment | Relatively heavy | Relatively heavy | Agent-based mode | Lightweight standalone deployment |
If your team depends heavily on the PostgreSQL ecosystem, TimescaleDB is often easier to adopt. If you are dealing with million-scale device connectivity and edge-cloud collaboration, IoTDB is closer to the actual problem.
 AI Visual Insight: This image serves as a technical overview of time-series databases. It highlights the relationship between continuous data collection, centralized storage, and analytics in Industrial IoT, making it a strong visual entry point for the concept of high-frequency device-side sampling flowing into a time-series engine.
AI Visual Insight: This image serves as a technical overview of time-series databases. It highlights the relationship between continuous data collection, centralized storage, and analytics in Industrial IoT, making it a strong visual entry point for the concept of high-frequency device-side sampling flowing into a time-series engine.
Storage engine design determines long-term cost and performance ceilings
In time-series workloads, fast writes are only the starting point. Compression efficiency and scan scope matter just as much. IoTDB’s TsFile organizes data along both device and time dimensions, which can significantly reduce unnecessary I/O during single-device queries.
TsFile structure
- File MetaData: File-level metadata
- Device MetaData Index: Device index
- ChunkGroup: Device-grouped data blocks
- Chunk/Page: Columnar organization and encoded compression by measurement
- Footer: Statistics and validation informationThis structure explains how TsFile improves both write and read efficiency through device grouping and columnar encoding.
By comparison, InfluxDB can face index pressure in high-cardinality scenarios. TimescaleDB inherits the advantages of SQL, but in extreme write-heavy workloads, the overhead of transactions and the relational model is harder to eliminate completely.
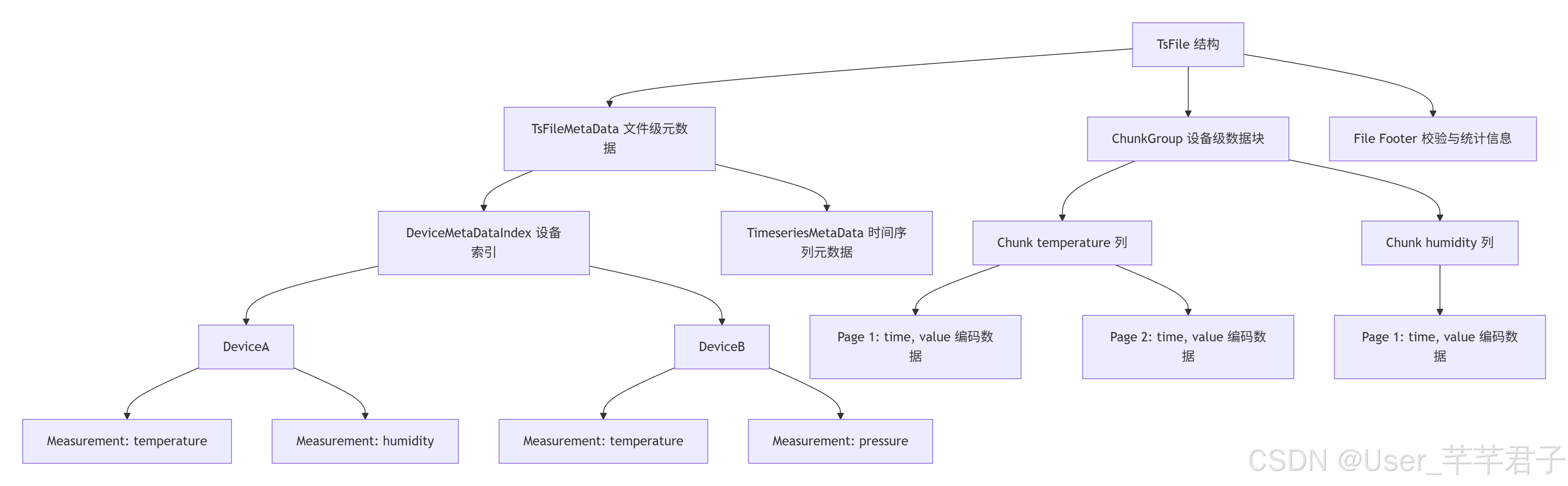 AI Visual Insight: This diagram emphasizes TsFile’s layered internal structure, including file metadata, the device index, ChunkGroup, and Page relationships. It shows how IoTDB uses device grouping and columnar encoding to compress data and reduce query scan scope.
AI Visual Insight: This diagram emphasizes TsFile’s layered internal structure, including file metadata, the device index, ChunkGroup, and Page relationships. It shows how IoTDB uses device grouping and columnar encoding to compress data and reduce query scan scope.
Query expressiveness directly affects developer productivity
A typical question is: how do you query the average temperature every five minutes over the last hour for a given factory? Different databases can all solve it, but the complexity of expression varies.
SELECT avg(temperature) AS avg_temp
FROM root.factory.*.temperature
GROUP BY ([now() - 1h, now()), 5m)
ALIGN BY DEVICE;This IoTDB SQL query uses a path wildcard to directly cover all devices under the factory, which fits a hierarchical device model well.
In IoTDB, root.factory.*.temperature is itself business semantics. You do not need extra JOIN operations, and you reduce the mental overhead of tag-based filtering. In industrial environments, the path is the model, and the model is the query entry point.
Apache IoTDB’s core competitiveness comes from the coordinated design of its data model and system architecture
IoTDB does not optimize just one layer. It connects data modeling, storage encoding, cluster scaling, and edge-cloud synchronization into a complete chain. That is the fundamental reason it has stronger advantages in Industrial IoT.
The hierarchical data model maps naturally to device topology
root.factory_a.workshop_01.device_001.temperature
root.factory_a.workshop_01.device_001.humidity
root.factory_a.workshop_02.device_003.speedThese paths naturally express the hierarchy of enterprise, workshop, device, and measurement point, which helps with access control, batch queries, and schema governance.
Batch writes and encoded compression jointly support high throughput
try (ISessionPool pool = new SessionPool.Builder()
.host("127.0.0.1")
.port(6667)
.user("root")
.password("root")
.build()) {
// Build batch writes for multiple measurements under the same device
Tablet tablet = new Tablet(
"root.factory_a.workshop_01.device_001",
java.util.Arrays.asList("temperature", "humidity"),
java.util.Arrays.asList(TSDataType.FLOAT, TSDataType.FLOAT),
1000);
for (int i = 0; i < 1000; i++) {
tablet.addTimestamp(i, System.currentTimeMillis() + i); // Write timestamps
tablet.addValue("temperature", i, 25.0f + i * 0.01f); // Write temperature data
tablet.addValue("humidity", i, 60.0f + i * 0.01f); // Write humidity data
tablet.rowSize++; // Maintain the current batch row count
}
pool.insertTablet(tablet); // Submit in batch to reduce network and transaction overhead
}This code shows how the IoTDB Java SDK uses Tablet for efficient batch ingestion.
For encoding, integers and floating-point values can use GORILLA, booleans can use RLE, and text can use dictionary encoding. Based on the practical figures provided in the source content, typical industrial sensor data can achieve compression ratios of 10:1 to 20:1.
Native distribution and edge-cloud collaboration define IoTDB’s engineering ceiling
IoTDB uses ConfigNode to manage metadata and DataNode to handle reads, writes, and sharded data storage. The Region mechanism manages data partitioning and multi-replica fault tolerance, giving IoTDB horizontal scalability and node migration capabilities.
SHOW DATANODES;
SHOW REGIONS;
MOVE REGION 1 TO DATANODE 3;These commands let you inspect node status, review data distribution, and manually trigger Region migration.
If your scenario includes edge sites, IoTDB also supports synchronizing data from edge instances to the cloud through Pipe, balancing local real-time responsiveness with centralized analytics. Many general-purpose TSDBs do not support this as naturally.
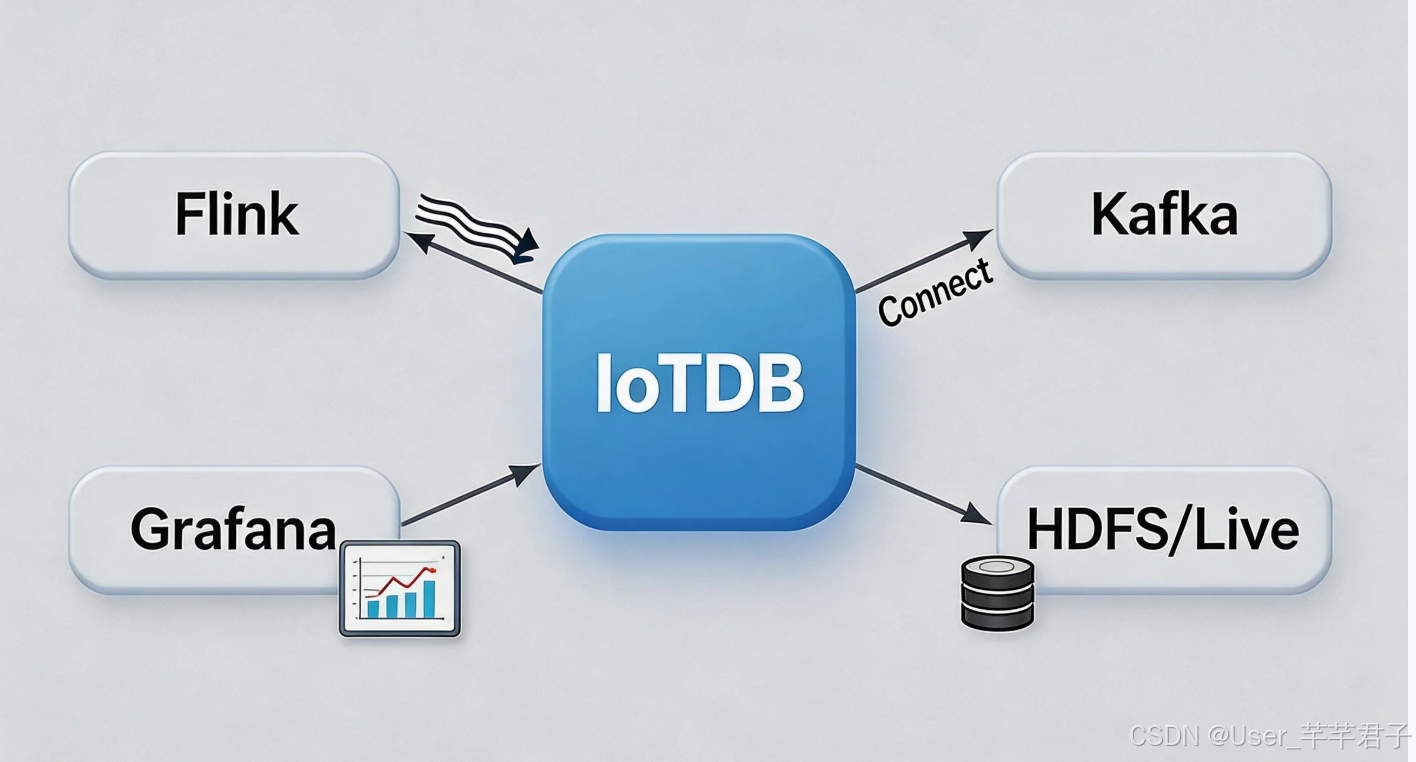 AI Visual Insight: This image shows how a time-series database connects to the analytics ecosystem. It highlights IoTDB as a data foundation that can integrate with tools such as Spark, Flink, and Grafana to create a closed loop for offline analytics, real-time processing, and visualization.
AI Visual Insight: This image shows how a time-series database connects to the analytics ecosystem. It highlights IoTDB as a data foundation that can integrate with tools such as Spark, Flink, and Grafana to create a closed loop for offline analytics, real-time processing, and visualization.
Selection recommendations should converge step by step around scenario constraints
For smaller-scale measurement workloads with a strong emphasis on complex SQL, prioritize TimescaleDB. If your primary focus is monitoring metric collection, Prometheus remains highly efficient. For medium- to large-scale Industrial IoT, complex device hierarchies, edge nodes, or long-term storage pressure, IoTDB deserves priority validation.
Simplified decision path
1. Start with measurement scale and peak write throughput
2. Then determine whether queries are mainly SQL analytics or path-based aggregation
3. Decide whether you need a native cluster and multi-replica support
4. Decide whether you need standalone edge deployment and synchronization
5. Finally compare ecosystem fit, team skills, and operational costThis path works well as a technical pre-screening framework before a proof of concept.
FAQ
1. Why is Apache IoTDB a better fit for Industrial IoT scenarios?
Because industrial data naturally features device hierarchies, continuous time-series patterns, and high-frequency writes. IoTDB’s hierarchical model, TsFile, native distributed architecture, and edge-cloud synchronization directly match these constraints.
2. What is the core dividing line between TimescaleDB and IoTDB?
If your business depends heavily on the PostgreSQL ecosystem and complex SQL analytics, TimescaleDB is usually more convenient. If your priorities are massive device connectivity, compression cost, path-based queries, and edge collaboration, IoTDB is the better fit.
3. What is the most commonly overlooked metric during database selection?
It is not peak single-point write throughput. The real question is whether write performance, compression, query efficiency, scalability, and synchronization can all succeed at the same time. Many solutions perform well in isolated benchmarks but reveal weaknesses in real production pipelines.
Core Summary
This article examines time-series database selection by systematically comparing the architectural paradigms, storage engines, query capabilities, and edge-cloud collaboration features of InfluxDB, TimescaleDB, Prometheus, and Apache IoTDB, and provides practical recommendations for large-scale Industrial IoT deployments.