The core value of Redis is not simply “storing data in memory,” but “sharing hot data over the network.” It addresses process isolation in distributed systems, database performance bottlenecks, and hot-access pressure, while working with MySQL in a layered caching architecture. Keywords: Redis, distributed systems, caching.
Technical Specification Snapshot
| Parameter | Details |
|---|---|
| Source Language | Chinese technical documentation |
| Languages Involved | Java, Python, Shell |
| Core Protocols | TCP/IP, HTTP, Redis RESP |
| Core Components | Redis, MySQL, Load Balancer |
| Typical Roles | Cache, Remote Memory, Read/Write Splitting Support |
| Star Count | Not provided in the source content |
| Core Dependencies | Network communication, in-memory storage, primary-replica replication |
Redis Must Be Understood in a Distributed Context
If your program runs on only one machine and within a single process, local variables are always more direct than Redis. Variables require no network hop and no serialization overhead, so for single-node scenarios, local memory should be the first choice.
The real problem Redis solves is that multiple processes and multiple nodes cannot directly share memory. Distributed systems naturally enforce process isolation, and variables on different hosts are invisible to one another. In that case, you need a unified data access entry point exposed over the network.
Redis Is Essentially Remote Shared Memory
You can think of Redis as an in-memory database accessed over the network. Business processes write hot data into Redis, and other processes read the same data over TCP, enabling cross-machine sharing.
import redis
# Connect to the Redis service, which is equivalent to connecting to remote shared memory
client = redis.Redis(host="127.0.0.1", port=6379, decode_responses=True)
# Store session state; this kind of hot data is a good fit for caching
client.set("session:user:1001", "token-abc", ex=1800) # Set an expiration time to prevent stale data from lingering
# Read shared data; multiple application instances can access it
session = client.get("session:user:1001")
print(session)This code demonstrates the minimal usage of Redis as a cross-process shared data layer.
Single-Node Architecture Remains Effective in Many Early-Stage Systems
Single-node architecture is not outdated. It typically deploys the application service and database service on a limited number of nodes, keeping the structure simple, operations costs low, and troubleshooting paths short. That makes it ideal for the early stage of a business.
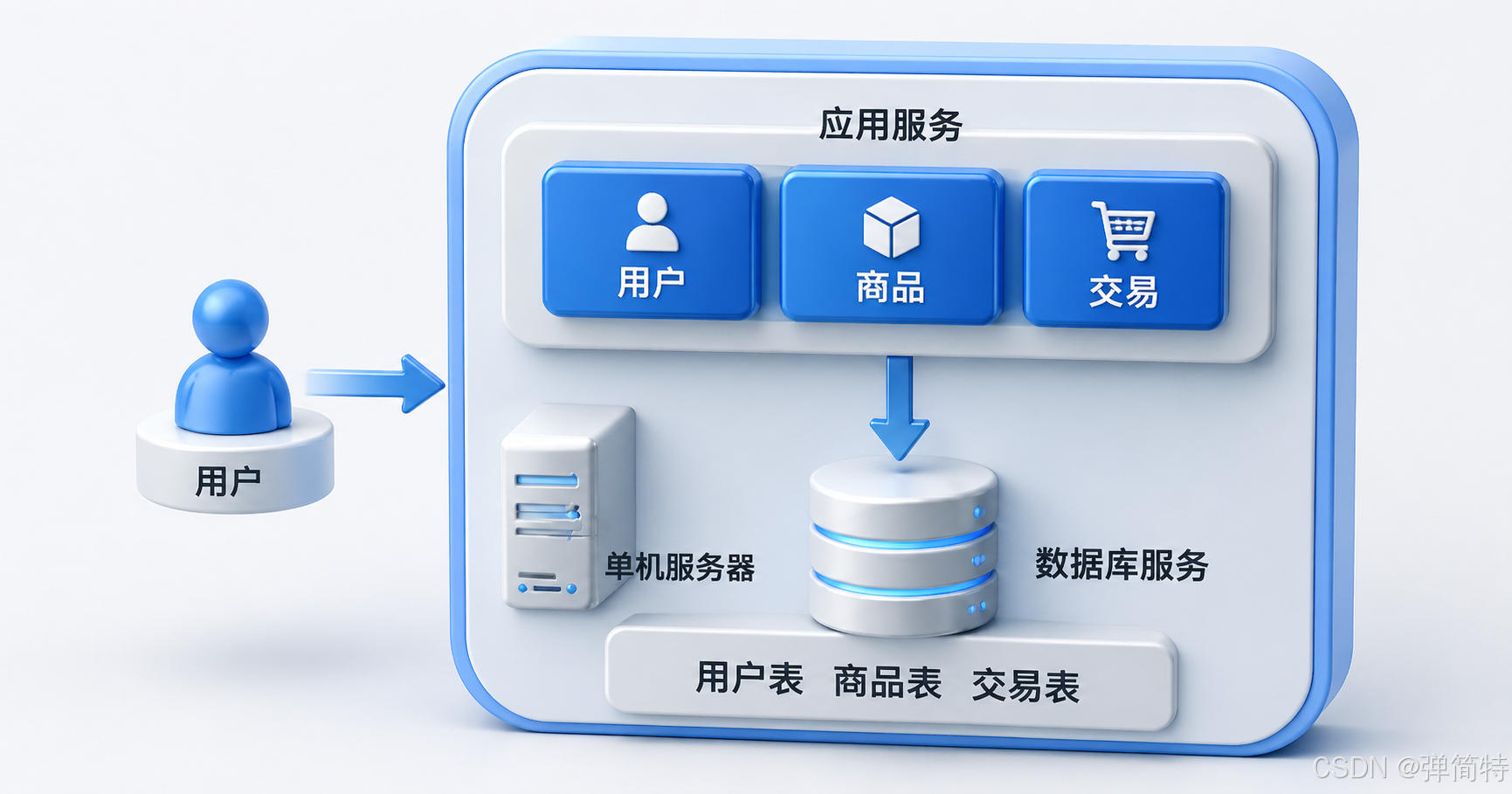 AI Visual Insight: The image shows an architecture in which the application service and database service are concentrated in a single node or deployment unit. The data access path is the shortest and the number of components is minimal, but compute, storage, and network resources compete with one another, leaving limited room for future scaling.
AI Visual Insight: The image shows an architecture in which the application service and database service are concentrated in a single node or deployment unit. The data access path is the shortest and the number of components is minimal, but compute, storage, and network resources compete with one another, leaving limited room for future scaling.
As request volume continues to grow, CPU, memory, disk I/O, and bandwidth gradually reach their limits. At that point, the bottleneck is no longer whether the code is functionally complete, but whether the resource ceiling of a single machine can support continued growth.
Distributed Evolution Usually Starts with Service Separation
The first step is often not microservices, but separating the application from the database. This allows application nodes to focus on computation and database nodes to focus on storage and queries, so they no longer compete for the same hardware resources.
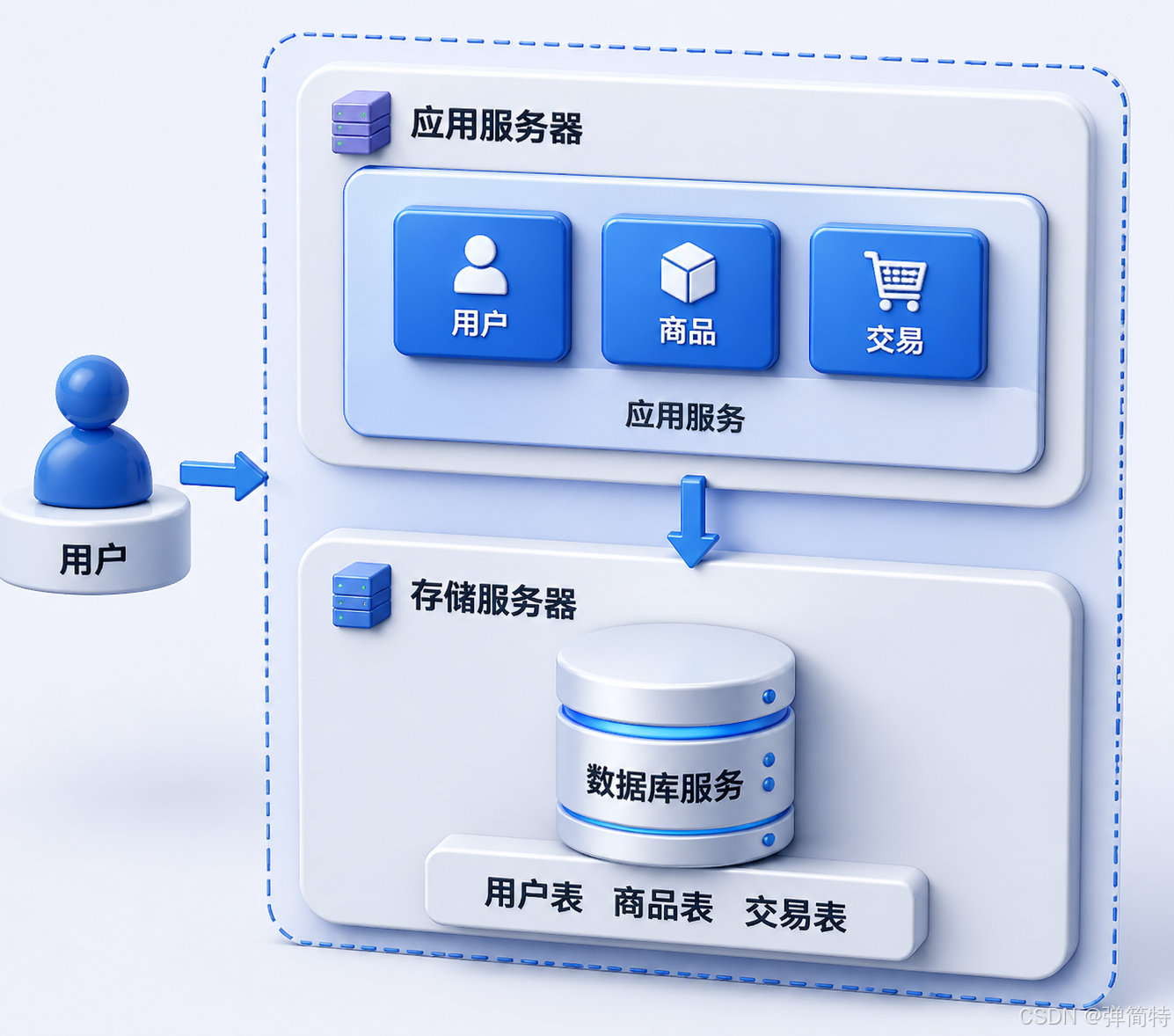 AI Visual Insight: The image shows a two-layer structure after the application layer and data layer are distributed across different hosts. The upper layer handles business requests, while the lower layer manages persistent storage. This split reduces resource contention and allows CPU, memory, and disk to be provisioned according to each service’s characteristics.
AI Visual Insight: The image shows a two-layer structure after the application layer and data layer are distributed across different hosts. The upper layer handles business requests, while the lower layer manages persistent storage. This split reduces resource contention and allows CPU, memory, and disk to be provisioned according to each service’s characteristics.
# Example: basic connectivity checks after deploying the application and database on separate machines
ping db-server.local
nc -zv db-server.local 3306 # Check whether the database port is reachable
redis-cli -h redis-server.local -p 6379 ping # Check whether the cache node is availableThese commands verify basic network reachability after distributed separation.
High-Concurrency Pressure Pushes the System into the Cluster Stage
When a single application server can no longer handle incoming traffic, the most direct solution is horizontal scaling: add more application instances. Then place a load balancer in front of them to distribute requests across nodes using round-robin or hash-based strategies.
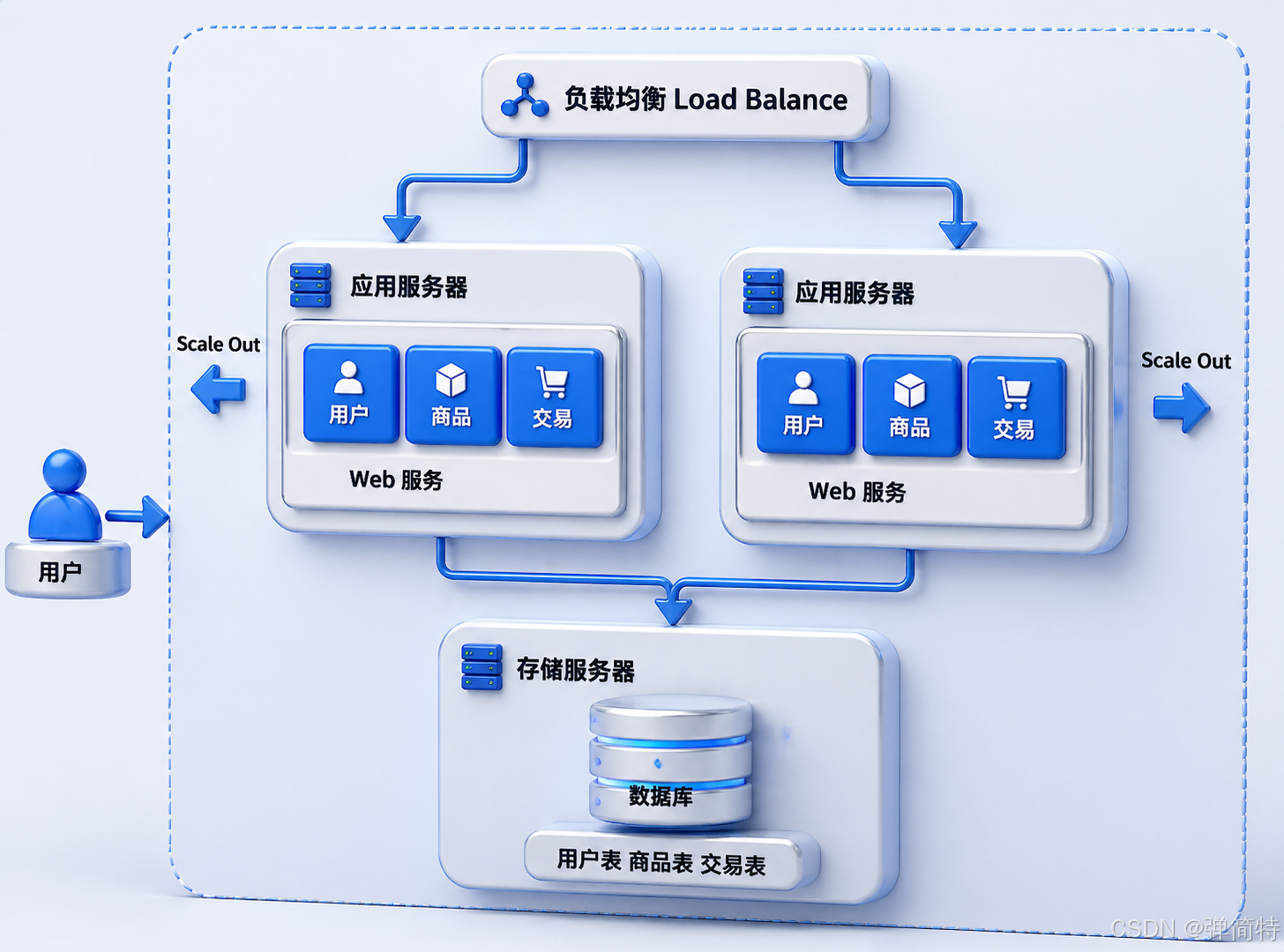 AI Visual Insight: The image shows a typical structure with an entry layer and a multi-instance application layer. Requests first enter the load balancer, which then distributes them evenly across multiple application nodes. This structure primarily addresses insufficient concurrency capacity in the application layer.
AI Visual Insight: The image shows a typical structure with an entry layer and a multi-instance application layer. Requests first enter the load balancer, which then distributes them evenly across multiple application nodes. This structure primarily addresses insufficient concurrency capacity in the application layer.
A load balancer handles forwarding, while application servers execute business logic. The former is usually much lighter, so a single load balancer node often handles more pressure than a single application node.
The Database Becomes the Next Bottleneck
After scaling the application layer, the database often becomes the next single pressure point. All application nodes still need to read from and write to the database, which concentrates traffic on the storage layer.
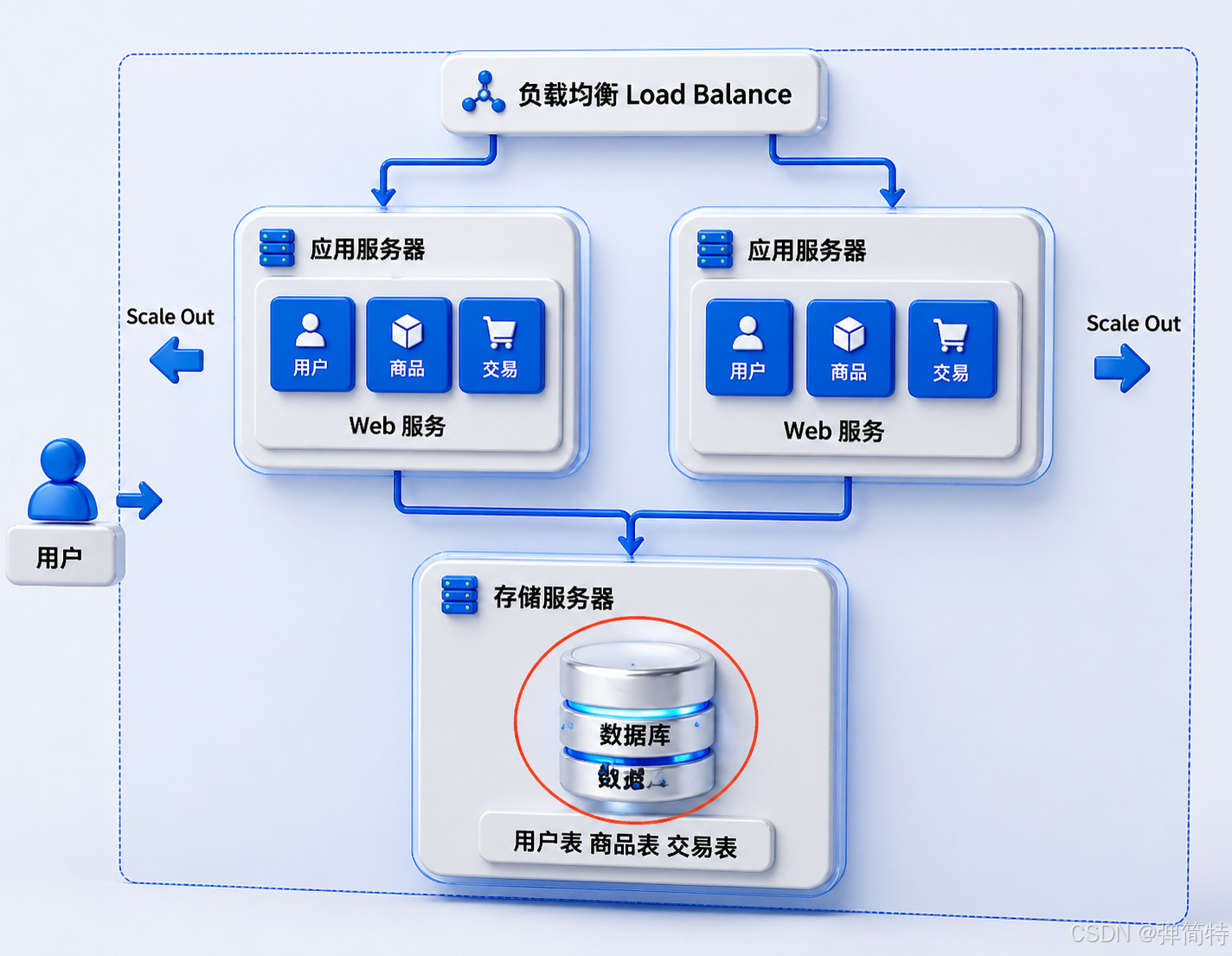 AI Visual Insight: The image highlights the structural bottleneck created when multiple application servers converge on a single database node. It shows that scaling the application tier does not automatically scale the entire system, because the storage layer may still define the throughput ceiling.
AI Visual Insight: The image highlights the structural bottleneck created when multiple application servers converge on a single database node. It shows that scaling the application tier does not automatically scale the entire system, because the storage layer may still define the throughput ceiling.
Read/Write Splitting and Cache Layering Are the Key Stage for Redis
A common way to scale databases is to use a primary-replica architecture. The primary handles writes, while replicas handle queries, distributing read pressure through replication. This pattern fits the read-heavy nature of many internet applications.
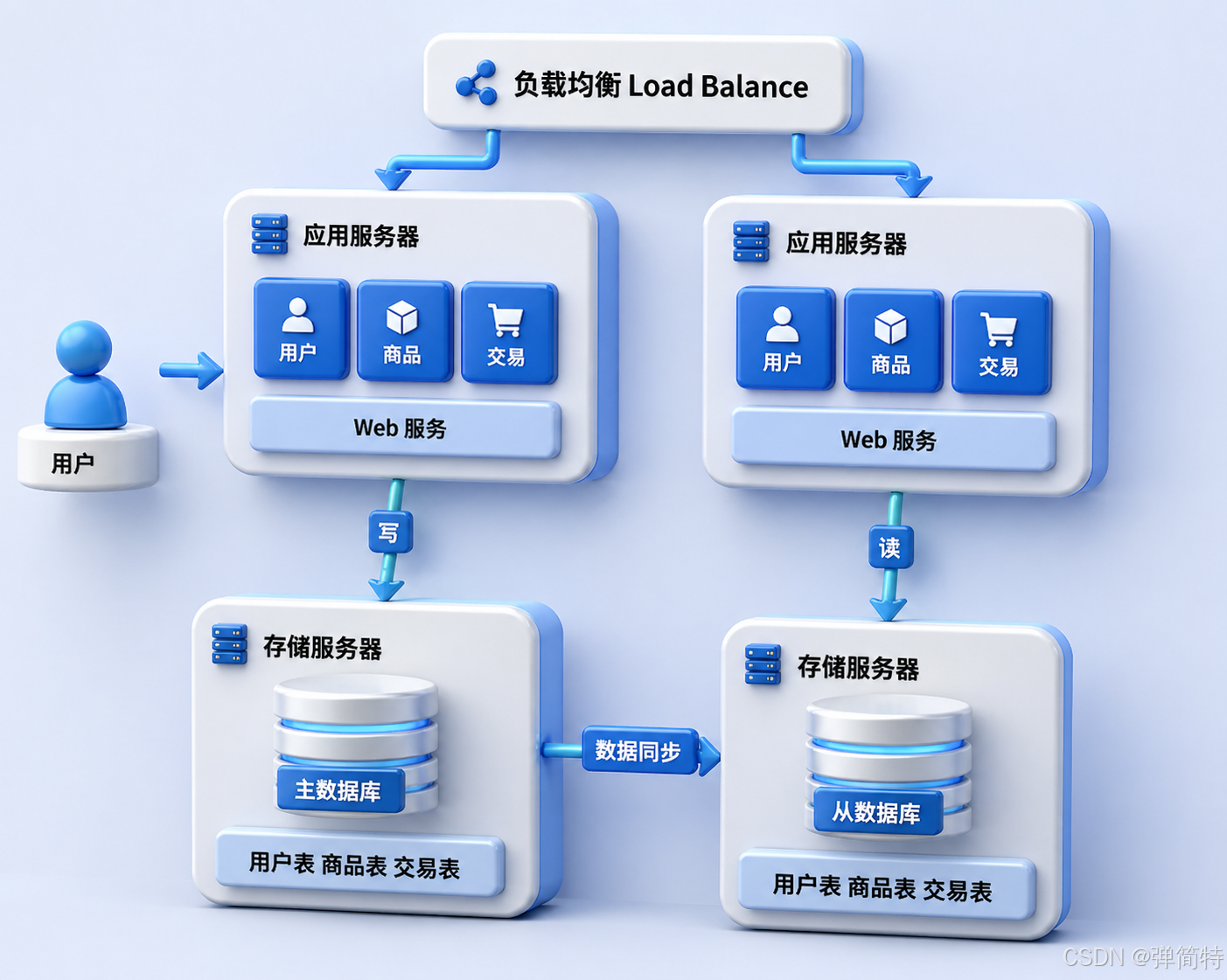 AI Visual Insight: The image shows a topology in which the primary database handles writes and multiple replicas handle reads. The application layer can route query traffic to replicas, reducing read pressure on the primary under high concurrency.
AI Visual Insight: The image shows a topology in which the primary database handles writes and multiple replicas handle reads. The application layer can route query traffic to replicas, reducing read pressure on the primary under high concurrency.
Even so, databases still center on disk-based persistence, and their response latency is usually higher than pure in-memory access. That is why a cache layer is introduced, with Redis becoming the first access point for hot data.
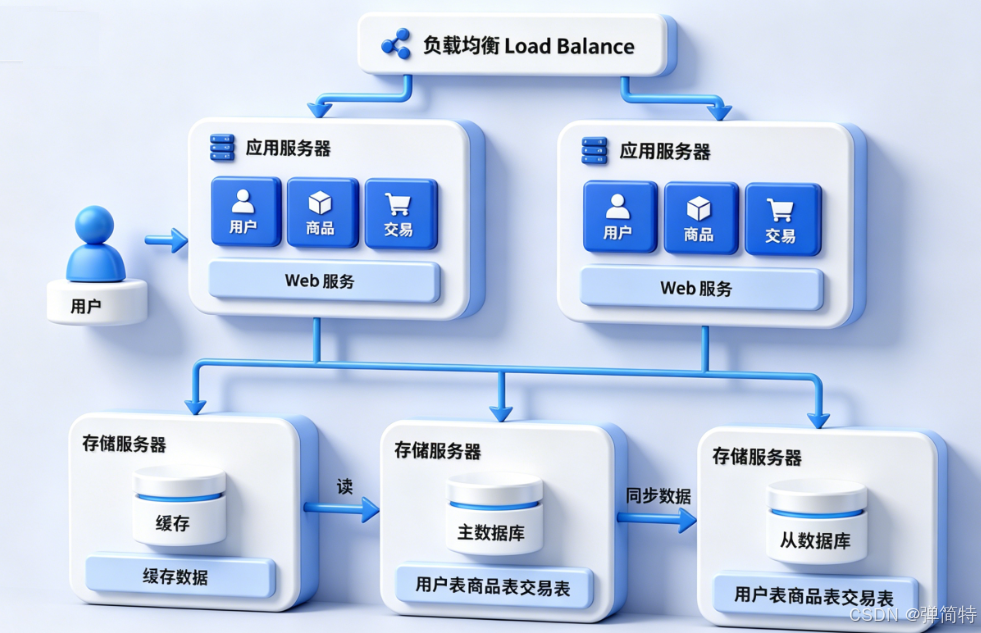 AI Visual Insight: The image illustrates the classic path in which requests check the cache first, fall back to the database on a miss, and then write the result back to the cache. This is the typical Cache-Aside pattern used to absorb traffic spikes, reduce latency, and lower direct database pressure.
AI Visual Insight: The image illustrates the classic path in which requests check the cache first, fall back to the database on a miss, and then write the result back to the cache. This is the typical Cache-Aside pattern used to absorb traffic spikes, reduce latency, and lower direct database pressure.
public String queryProduct(String productId) {
String key = "product:" + productId;
String cached = redis.get(key); // Check the cache first and return immediately on a hit
if (cached != null) {
return cached;
}
String value = mysql.query(productId); // Cache miss: fall back to the database
redis.setex(key, 300, value); // Write back to the cache and set an expiration time
return value;
}This code reflects the most common cache-aside read flow.
Redis and MySQL Are Not Replacements, but a Layered Collaboration
Redis is well-suited for hot, small, low-latency data such as sessions, leaderboards, verification codes, and flash-sale inventory. MySQL is better suited for full, persistent, structured business data such as orders, users, and transaction records.
Together, they align with the Pareto principle: a small amount of hot data serves most requests. But this also introduces trade-offs. The classic challenge is cache-database dual-write consistency, which is often where distributed system complexity starts to rise.
Massive Data Volume and Team Collaboration Continue to Drive Architectural Evolution
As data volume continues to grow, a single database instance may hit its capacity limit before anything else. At that point, you need database and table sharding, distributing databases or tables across multiple nodes.
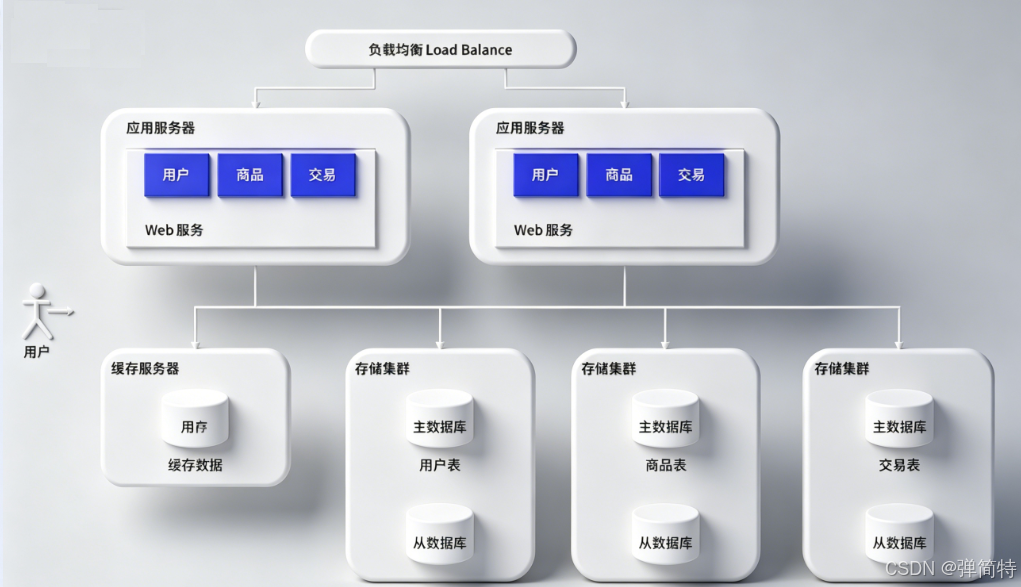 AI Visual Insight: The image shows how data that was originally concentrated in a single database is split horizontally or vertically across multiple nodes. This approach addresses oversized tables, oversized databases, and insufficient storage capacity.
AI Visual Insight: The image shows how data that was originally concentrated in a single database is split horizontally or vertically across multiple nodes. This approach addresses oversized tables, oversized databases, and insufficient storage capacity.
If the application code also grows into a monolith, team collaboration becomes inefficient. The next step is often microservices, so capabilities such as users, products, orders, and payments can be deployed and scaled independently.
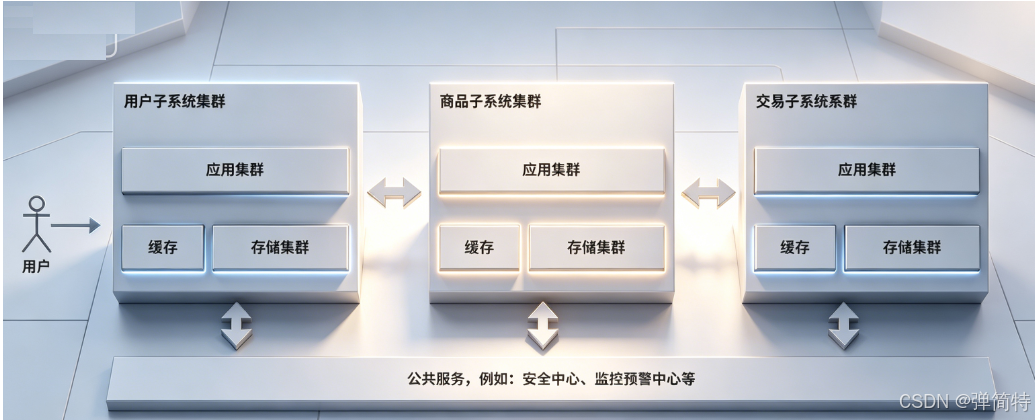 AI Visual Insight: The image shows how a monolithic application is decomposed into multiple services with clear responsibilities. These services collaborate through network communication, making independent development, deployment, and scaling easier, while significantly increasing system governance complexity.
AI Visual Insight: The image shows how a monolithic application is decomposed into multiple services with clear responsibilities. These services collaborate through network communication, making independent development, deployment, and scaling easier, while significantly increasing system governance complexity.
The Standard for Distributed Systems Is Not “Advanced,” but “Necessary”
Introducing Redis, read/write splitting, sharding, and microservices is not about showing off architectural sophistication. It is about solving specific bottlenecks. The core principle of architecture design is not that more complexity is always better, but that the solution should be just sufficient for the current stage of the business.
Several Metrics Are Essential in Distributed Systems
Availability describes the proportion of total time during which the system can serve normally. Response time describes how long a single request takes to complete. Throughput or concurrency describes how many requests the system can process per unit of time.
These three metrics determine the direction of architectural evolution: if latency is high, inspect caching and I/O first; if throughput is low, look at scaling and traffic distribution first; if availability is poor, add redundancy and failover first.
FAQ
FAQ 1: What Is the Biggest Difference Between Redis and Local Variables?
Answer: Local variables are visible only within a single process. They are faster, but they cannot be shared across hosts. Redis provides a unified access entry point over the network, making it suitable for shared state and hot data in distributed systems.
FAQ 2: Why Do High-Concurrency Systems Usually Not Rely Only on Redis?
Answer: Redis memory is expensive, capacity is limited, and persistence is not its only advantage. Redis is ideal for handling hot traffic, but full business data should still be managed by persistent databases such as MySQL.
FAQ 3: When Should You Introduce Redis?
Answer: Redis is the right choice when the system already shows clear hot-read patterns, the database is under heavy pressure, cross-instance shared state is difficult, or the business requires millisecond-level access latency. For small single-node systems, simplicity should come first.
Core Summary: This article explains the real value of Redis from the perspective of distributed systems. Redis is not a replacement for local variables, but a high-performance in-memory middleware layer for sharing data across multiple processes and hosts. It also walks through the evolution path from single-node systems to load balancing, read/write splitting, caching, sharding, and microservices.